
Chinese, Simplified
- 概述
- 动机
- 神经检索
- 检索增强生成(RAG)流水线
- RAG的好处
- RAG与微调
- RAG合奏
- 使用特征矩阵选择矢量数据库
- 构建RAG管道
- 摄入
- Chucking
- 嵌入
- 句子嵌入:内容和原因
- 背景:与BERT等代币级别模型相比的差异
- 相关:句子转换器的训练过程与令牌级嵌入模型
- 句子变换器在RAG中的应用
- 句子嵌入:内容和原因
- 检索
- 标准/天真的方法
- 优势
- 缺点
- 语句窗口检索/从小到大分块
- 优势
- 缺点
- 自动合并检索器/层次检索器
- 优势
- 缺点
- 计算出理想的块大小
- 寻回器镶嵌和重新排列
- 使用近似最近邻进行检索
- 重新排序
- 标准/天真的方法
- 响应生成/合成
- 迷失在中间:语言模型如何使用长上下文
- “大海捞针”测试
- 摄入
- 组件式评估
- 检索度量
- 上下文精度
- 上下文回忆
- 上下文相关性
- 生成度量
- 脚踏实地
- 回答相关性
- 端到端评估
- 回答语义相似性
- 答案正确性
- 检索度量
- 多模式RAG
- 改进RAG系统
- 相关论文
- 知识密集型NLP任务的检索增强生成
- 主动检索增强生成
- 多模式检索增强生成器
- 假设文档嵌入(HyDE)
- RAGAS:检索增强生成的自动评估
- 微调还是检索?LLM中知识注入的比较
- 密集X检索:我们应该使用什么检索粒度?
- ARES:一种用于检索增强生成系统的自动评估框架
- 引用
组件式评估
- LLM的RAG系统中的组件评估包括单独评估系统的各个组件。这种方法通常检查检索组件和生成组件的性能,检索组件从数据库或语料库中获取相关信息,生成组件基于检索到的数据合成响应。通过单独评估这些组成部分,研究人员可以确定整个RAG系统中需要改进的特定领域,从而在LLM中实现更高效、更准确的信息检索和响应生成。
- 虽然上下文精度、上下文回忆和上下文相关性等指标可以深入了解RAG系统的检索组件的性能,但基础性和答案相关性可以了解生成的质量。
- 明确地
- 评估检索的指标:上下文相关性、上下文回忆和上下文精度,它们共同评估响应用户查询检索到的信息的相关性、完整性和准确性。Context Precision侧重于系统对相关项目进行更高排名的能力,Context Recall评估系统检索上下文所有相关部分的效果,Context Correlation衡量检索到的信息与用户查询的一致性。这些指标确保了检索系统在提供最相关和最完整的上下文以生成准确响应方面的有效性。
- 评估生成的指标:可信度和答案相关性,分别衡量生成的答案与给定上下文的事实一致性及其与原始问题的相关性。忠实注重答案的事实准确性,确保所有的说法都能从给定的上下文中推断出来。答案相关性评估答案在多大程度上解决了最初的问题,从而惩罚了不完整或多余的回答。这些度量确保生成组件生成上下文适当且语义相关的答案。
- 这四个方面的调和平均值为您提供了总体分数(也称为ragas分数),这是衡量RAG系统在所有重要方面性能的单一指标。
- 大多数测量不需要任何标记的数据,这使得用户更容易运行它,而不用担心首先构建人工注释的测试数据集。为了运行ragas,您只需要几个问题,如果您使用context_recall,则需要一个参考答案。
- 总的来说,这些指标提供了RAG系统检索性能的全面视图,可以使用用于评估RAG管道(如Ragas或TruLens)的库来实现,并提供有关RAG管道性能的详细见解,重点关注检索和生成的内容在上下文和事实上对用户查询的响应。具体来说,Ragas提供了专门为单独评估RAG管道的每个组件而定制的指标。这种方法补充了对您的系统进行更广泛的系统级端到端评估(详见端到端评价),使您能够更深入地了解RAG系统在复杂的上下文和事实准确性至关重要的现实场景中的表现。下图(来源)显示了Ragas提供的指标,这些指标是为单独评估RAG管道的每个组件(检索、生成)而定制的。

- 下图(来源)显示了可用于评估RAG的“三重”指标:基础性(也称为可信度)、答案相关性和上下文相关性。请注意,上下文精确性和上下文回忆也很重要,最近在Ragas的新版本中引入了它们。

检索度量
- 在LLM的背景下评估RAG的检索组件包括评估系统检索相关信息的有效性,以支持生成准确且符合上下文的响应。
上下文精度
- 类别:上下文对齐和精度
- 重点:评估RAG系统在结果中排名较高的背景下对地面实况相关项目进行排名的准确性。在响应查询时,确定最相关的信息块是否按优先级排列在最前列至关重要。
- 测量方法:使用一个公式,该公式考虑了前K个结果中是否存在真阳性(相关项目排名正确)和假阳性(无关项目排名错误)。这通常使用问题及其上下文信息进行评估。
- 评估方法:通过首先识别上下文的前K个块中的真阳性和假阳性,然后计算K处的精度来计算度量。上下文精度的公式如下:

- 其中k表示上下文中考虑的块的总数。上下文精度的值介于0和1之间,分数越高表示上下文与查询的相关项的对齐越精确。
上下文回忆
- 类别:上下文对齐和回忆
- 焦点:评估RAG系统检索到的上下文与注释答案一致的程度,被视为基本事实。它专门衡量系统检索与基本事实答案直接相关的上下文所有相关部分的能力。
- 测量方法:通过分析基本事实答案中的句子与检索到的上下文之间的对应关系来计算上下文回忆。它可以使用评估基本事实句子对检索到的上下文的归因的方法来测量。
- 评估方法:这个过程包括识别基本事实答案中的每一句话,并确定它是否在检索到的上下文中表示。上下文召回的计算公式如下:
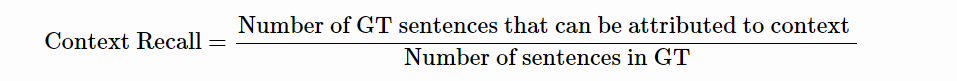
- 实例
- 问题:法国在哪里,首都是什么?
- 基本事实:法国位于西欧,首都是巴黎。
- 高上下文回忆示例:上下文包括法国在西欧的信息,并提到巴黎是其首都。
- 低语境回忆示例:语境谈论法国的地理特征和历史,但没有提及其首都。
- 在该度量中,值的范围在0和1之间,值越高表示在将检索到的上下文与基本事实答案对齐方面的性能越好。
上下文相关性
- 类别:上下文一致性和相关性
- 集中
- “返回的段落是否与回答给定的问题相关?”
- 测量RAG系统检索的上下文或内容与用户查询的一致性。它专门评估检索到的信息是否与给定的查询相关和合适,确保只包括基本信息以有效地处理查询。
- 测量方法:可以使用较小的BERT风格模型、嵌入距离或LLM进行测量。该方法包括通过识别检索到的上下文中与回答给定问题直接相关的句子来估计上下文相关性的值。
- 评估方法:包括两个步骤:首先,使用语义相似性度量来识别相关句子,为每个句子生成相关性得分。接下来是对整体上下文相关性的量化,其中使用以下公式计算最终得分:

- 示例:
- 高度语境相关性的例子:对于“法国的首都是什么?”这样的问题,高度相关的语境是“西欧的法国包括中世纪城市、高山村庄和地中海海滩。其首都巴黎以其时装店、包括卢浮宫在内的古典艺术博物馆和埃菲尔铁塔等纪念碑而闻名。”
- 低上下文相关性示例:对于同一个问题,不太相关的上下文将包括额外的、不相关的信息,例如“该国也以其葡萄酒和精致的美食而闻名。拉斯科的古代洞穴绘画、里昂的罗马剧院和广阔的凡尔赛宫证明了其丰富的历史。”
- 该指标确保RAG系统提供简洁且直接相关的信息,提高了对特定查询的响应的效率和准确性。
生成度量
- 在LLM的背景下评估RAG的生成部分包括评估系统将检索到的信息无缝集成到连贯、上下文相关和语言准确的响应中的能力,确保检索到的数据和生成语言技能的和谐融合。简单地说,这些指标共同提供了一种细致入微的多维方法来评估RAG系统,不仅强调信息的检索,还强调其上下文相关性、事实准确性以及与用户查询的语义一致性。
脚踏实地
- 类别:事实一致与语义相似
- 集中
- “生成的答案是否忠实于检索到的段落?或者它是否包含段落之外的幻觉或推断陈述?”
- 该度量评估模型的响应和检索到的文档之间的事实一致性和语义相似性。它确保生成的响应在上下文中是适当的,并以检索到的信息为事实依据。具体来说,它评估模型答案中的所有声明是否可以直接从给定的上下文中推断出来。
- 测量方法:可以使用自然语言推理(NLI)模型、大型语言模型(LLM)以及自动化系统和人类判断的组合来测量基础性。忠诚度得分是通过将生成的答案中的主张与给定上下文中的主张进行比较来计算的,使用以下公式:

- 评估方法:利用思维链(CoT)提示来模拟推理过程,通过自动化系统(用于语义匹配和事实核查)和人类判断的混合方法,在0或1的范围内对对齐进行评分。评估过程包括从生成的答案中识别一组索赔,并将这些索赔中的每一项与给定的上下文进行交叉检查,以确定其事实一致性。
- 示例:
- 高忠实度的例子:对于“爱因斯坦是在哪里和什么时候出生的?”这个问题,在“阿尔伯特·爱因斯坦(1879年3月14日出生)是一位德国出生的理论物理学家”的背景下,高忠实度答案是“爱因斯坦1879年三月14日出生在德国。”
- 低忠诚度的例子:对于同样的问题和背景,低忠诚度的答案是“爱因斯坦于1879年3月20日出生在德国。”
- 这一指标对于确保RAG系统生成的响应的可靠性和可信度至关重要,因为它直接关系到响应查询提供的信息的准确性和事实一致性。
回答相关性
- 类别:反应质量和语义相关性
- 集中
- “给定查询和检索到的文章,生成的答案是否相关?”
- 此度量评估模型生成的答案与用户查询的相关性。它评估生成的答案与给定提示的相关性,惩罚不完整或包含冗余信息的答案。它不考虑事实,而是侧重于对最初问题的回答的直接性和适当性。
- 测量方法:使用BERT风格的模型、嵌入距离或LLM进行量化。该度量是使用从答案和原始问题生成的多个问题之间的平均余弦相似性来计算的,没有参考。此测量的公式为:

- 其中q是原始问题,qi是由答案生成的问题,sim表示它们的嵌入之间的余弦相似性。
- 评估过程:包括多次提示LLM为生成的答案生成适当的问题,然后测量这些生成的问题与原始问题之间的平均余弦相似性。其基本思想是,如果生成的答案准确地解决了最初的问题,LLM应该能够从与原始问题紧密一致的答案中生成问题。
- 示例:
- 低相关性答案示例:对于“法国在哪里,首都是什么?”这个问题,低相关性答案是“法国在西欧。”
- 高相关性答案示例:对于同一个问题,高相关性答案是“法国在西欧,巴黎是其首都。”
这一指标对于确保RAG系统提供的答案不仅准确,而且完整,直接解决用户的查询而不包括不必要的细节至关重要。
- 下图(来源)显示了Answer Correlation的输出格式。

端到端评估
- 评估管道的端到端性能也至关重要,因为它直接影响用户体验。Ragas提供了可用于评估管道整体性能的指标,确保进行全面评估。
回答语义相似性
- 类别:答案质量和语义一致性
- 焦点:评估RAG系统生成的答案与基本事实之间的语义相似程度。该指标专门评估生成的答案的含义与基本事实的含义的反映程度。
- 测量方法:使用交叉编码器模型来测量该度量,该模型旨在计算语义相似性得分。这些模型分析生成的答案和基本事实的语义内容。
- 评估方法:该方法包括将生成的答案与基本事实进行比较,以确定语义重叠的程度。语义相似性在0到1的范围内进行量化,其中得分越高表示生成的答案与基本事实之间的一致性越大。答案语义相似性的公式是隐含地基于语义重叠的评估,而不是直接的公式。
- 实例
- 基本事实:阿尔伯特·爱因斯坦的相对论彻底改变了我们对宇宙的理解。
- 高度相似的答案:爱因斯坦开创性的相对论改变了我们对宇宙的理解。
- 低相似性答案:艾萨克·牛顿的运动定律极大地影响了经典物理学。
- 在这个指标中,更高的分数反映了生成的响应在语义上与基本事实的接近程度方面的更好质量,这表明答案更准确且与上下文相关。
答案正确性
- 类别:答案的准确性和正确性
- 焦点:与基本事实相比,该指标评估RAG系统生成的答案的准确性。它不仅强调语义上的相似性,而且强调生成的答案相对于基本事实的事实正确性。
- 测量方法:评估答案的正确性包括评估语义相似性和事实相似性。使用加权方案来集成这些方面,加权方案可以包括使用交叉编码器模型或用于语义分析的其他复杂方法。用户还可以应用阈值以二进制方式解释分数。
- 评估方法:该方法需要将生成的答案与基本事实进行比较,以评估语义和事实的一致性。这两个方面的综合评估产生了答案正确性得分,其范围从0到1,其中得分越高表示准确性越高,并且与基本事实一致。
- 实例
- 基本事实:爱因斯坦1879年出生于德国。
- 答案正确率高的例子:1879年,爱因斯坦在德国出生。
- 答案正确率低的例子:爱因斯坦1879年出生于西班牙。
- 该指标强调了不仅要理解用户查询的上下文和内容(如上下文相关性评估),还要确保提供的答案在事实和语义上与既定事实一致,从而确保RAG系统的高质量响应的重要性。
原文地址
https://aman.ai/primers/ai/RAG/
Article



