软件设计
QQ群
视频号

微信

微信公众号

知识星球
- 162 次浏览
【联轴器】机械:联轴器类型
QQ群
视频号
微信
微信公众号
知识星球

联轴器是最常见的机械元件之一,因为它在动力传动系统中非常重要。因此,它们可用于各种应用程序和服务环境。
因此,多年来,设计师和工程师针对特定的使用条件和环境设计了许多不同的联轴器。
本文将使您熟悉不同类型的联轴器,并讨论为您的应用选择正确的选项。
目录
- I什么是联轴器?
- 二联轴器的用途
- 三联轴器类型
- 四、选择参数
什么是联轴器?
联轴器是一种机械装置,用于连接机器中相似或不同的轴,以传递动力和运动。它通常是一个临时连接(但在某些情况下可能是永久性的),并且能够移除以进行维修或更换。联轴器可以是刚性的,也可以是柔性的。
由于许多设计的可用性,两种类型的机械联轴器的结构和功能可能存在明显差异。有些联轴器可以在不移动轴的情况下连接到轴上,而大多数联轴器则需要移动轴才能安装。
在大多数情况下,与齿轮不同,联轴器不会改变运动方向或角速度。与离合器不同,它不能在操作过程中连接或断开。联轴器只能在短距离内传递扭矩,对于长距离而言,链条传动和皮带传动是更好的选择。联轴器通常与导螺杆组件配对,以将螺杆轴连接到电机上。
联轴器的工作原理是在两个轴之间始终保持牢固但灵活的连接,以将运动从一个轴传递到另一个轴。它在所有载荷值和未对准情况下都这样做,而不允许两轴之间有任何相对运动。
联轴器的用途
联轴器可以在机器中执行多种功能。在高级应用中,该设计可以将这些耦合特征中的一个以上结合到产品的功能中。
让我们简单看看这些是什么:
- 动力传输
- 减震
- 错位调节
- 热流中断
- 过载保护
动力传输
在大多数情况下,主要目的是将动力和扭矩从驱动轴传递到从动轴——例如,将电机连接到泵或压缩机的联轴器。
吸收冲击和振动
联轴器可以平滑从驱动元件到从动元件的任何冲击或振动。此功能减少了部件的磨损,并延长了装置的使用寿命。
适应任何错位
轴之间的错位可能是由于初始安装错误造成的,也可能是由于其他原因而随着时间的推移而发展。大多数联轴器可以适应轴之间一定程度的错位(轴向、角度和平行)。
中断热流
联轴器还可以中断连接轴之间的热量流动。如果原动机在运行过程中倾向于发热,则应保护驱动侧的机械免受这种热量的影响。
过载保护
被称为过载安全机械联轴器的特殊联轴器是为了过载保护而设计的。在感应到过载情况时,这些扭矩限制联轴器切断两轴之间的连接。它们要么滑动,要么断开,以保护敏感机器。
联轴器类型
联轴器有多种不同的形状和尺寸。其中一些适用于通用应用程序,而另一些则是为真正特定的场景定制的。
为了做出明智的选择,重要的是要了解不同类型联轴器的性能和差异。本节介绍了有关以下类型联轴器及其工作方式的信息:
- 刚性联轴器
- 挠性联轴器
- 套筒或套筒联轴器
- 分体式套筒联轴器
- 法兰联轴器
- 齿轮联轴器
- 万向节(胡克关节)
- Oldham联轴器
- 膜片联轴器
- 爪式联轴器
- 梁式联轴器
- 液力耦合器
刚性联轴器
顾名思义,刚性联轴器几乎不允许轴之间的相对运动。当需要精确对准时,工程师更喜欢刚性联轴器。
任何能够限制任何不希望的轴运动的联轴器都被称为刚性联轴器,因此,它是一个总括术语,包括不同的特定联轴器。这种联轴器的一些例子有套筒联轴器、压缩联轴器和法兰联轴器。
一旦使用刚性联轴器连接两个设备轴,它们就充当单个轴。刚性联轴器可用于垂直应用,如垂直泵。
它们还用于在诸如大型涡轮机的高扭矩应用中传递扭矩。它们不能使用柔性联轴器,因此,现在越来越多的涡轮机在涡轮机气缸之间使用刚性联轴器。这种布置确保了涡轮轴起到连续转子的作用。
挠性联轴器
任何能够允许组成轴之间进行某种程度的相对运动并提供振动隔离的联轴器都被称为柔性联轴器。如果轴始终完全对齐,并且机器在操作过程中没有移动或振动,则不需要柔性联轴器。
不幸的是,这不是机器在现实中的操作方式,设计师必须在机器设计中处理以上所有问题。例如,为了执行高速加工操作,CNC加工车床具有高精度和高速度要求。柔性联轴器可以通过减少振动和补偿错位来提高性能和精度。
这些联轴器可以减少机器上的磨损量,因为缺陷和动力学几乎是每个系统的一部分。额外的好处是,它们通常很容易安装,使用寿命长。
“挠性联轴器”也是一个总括术语,在其名称下包含许多特定的联轴器。这些联轴器构成了目前使用的大多数类型的联轴器。弹性联轴器的一些常见例子是齿轮联轴器、万向节和Oldham联轴器。
套筒或套筒联轴器
套筒联轴器是刚性联轴器中最简单的例子。它由铸铁套筒(空心圆柱体)或套筒组成。其内径等于所连接轴的外径。钩头键用于限制相对运动,防止轴和套筒之间滑动。
一些套筒联轴器和轴具有螺纹孔,这些螺纹孔在装配时匹配,以防止轴发生任何轴向移动。从一个轴到另一个轴的动力传递通过套筒、键槽和键进行。该联轴器用于轻至中等负载扭矩。
套筒联轴器几乎没有移动部件,因此只要所有部件的设计都考虑到预期的扭矩值,它就是一个坚固的选择。
分体式套筒联轴器
为了便于组装,套筒联轴器中的套筒可分为两部分。通过这样做,技术人员不再需要移动连接的轴来组装或拆卸联轴器。
这就是分体式套筒联轴器或压缩联轴器。套筒的两半用双头螺栓或螺栓固定到位。
类似于套筒联轴器,这些联轴器通过键传递动力。开口套筒联轴器用于重型应用。
法兰联轴器
在法兰联轴器中,一个法兰滑到每个要连接的轴上。法兰通过螺柱或螺栓相互固定,并通过键固定在轴上。使用固定螺钉或锥形键可确保法兰轮毂不会向后滑动并露出轴接口。
其中一个法兰的表面有一个突出的环,而另一个则有一个等效的凹槽来容纳它。这种结构有助于法兰(以及轴)保持对齐,而不会在轴上产生任何过度的应力。
法兰联轴器用于中型至重型应用。它们可以在两根管道之间形成有效的密封,因此,除了动力传输外,它们还用于加压流体系统。法兰联轴器主要有三种类型:
- 无保护型法兰联轴器
- 保护型法兰联轴器
- 船用法兰联轴器
齿轮联轴器

齿轮联轴器与法兰联轴器非常相似。然而,它是一种柔性联轴器,可用于非共线轴。齿轮联轴器可适应约2度的角度错位和0.25…0.5毫米的平行错位。
齿轮联轴器的设置包括两个轮毂(带外轮齿)、两个法兰套(带内轮齿)、密封件(O形圈和垫圈)和提供的紧固件。
联轴器两端之间的动力传递通过齿轮联轴器中的内齿轮和外齿轮进行。
齿轮联轴器能够进行高扭矩传输。因此,它们可用于重型应用。它们需要定期润滑(油脂)以获得最佳性能。
万向节(胡克关节)
当两个轴不平行并且以小角度相交时,我们使用万向节。这种接头可以适应较小的角度偏差,同时提供高扭矩传递能力。
万向节由一对通过横轴连接的铰链组成。这两个铰链彼此成90度放置。横轴保持此方向,并负责动力传递。万向节不是等速联轴器,即驱动轴和从动轴以不同的速度旋转。
它们可用于各种不同的应用程序,因此得名。万向节最常用于汽车变速箱和差速器。
Oldham联轴器
Oldham联轴器是一种专门用于横向轴错位的特殊联轴器。当两轴平行但不共线时,最适合使用Oldham联轴器。
该设计由两个滑动到轴上的法兰和一个称为中心圆盘的中间部分组成。中心制动盘的每个面上都有一个凸耳。这两个凸耳实际上是相互垂直的矩形突起,并安装在两侧法兰上的凹槽中。
法兰通过键固定在轴上。因此,动力传递从驱动轴到键到法兰到中心盘,然后通过第二法兰到从动轴。
Oldham联轴器非常适合两轴之间存在平行偏移的情况。在不同高度的轴之间需要动力传输的情况下,可能会发生这种平行错位。当轴运动时,中心圆盘来回移动,并根据横向变化进行调整。
膜片联轴器
膜片联轴器是非常好的全能联轴器。它们可以适应平行未对准以及高角度和轴向未对准。它们还具有高扭矩能力,可以在不需要润滑的情况下高速传递扭矩。
膜片联轴器有多种样式和尺寸可供选择。该结构由两个隔板组成,隔板之间有一个中间构件。隔膜基本上是一个或多个柔性板或金属膜,通过两侧的螺栓将轴上的驱动法兰连接到中间构件。
膜片联轴器最初是为直升机驱动轴开发的。但多年来,它们在其他旋转设备中也有很大的用途。由于其高速功能,它们最常用于涡轮机。目前的应用包括涡轮机、压缩机、发电机、飞机等。
爪式联轴器
爪形联轴器是一种材料挠性联轴器。它可用于一般的低功率传输和运动控制应用。它可以适应任何角度偏差。与膜片联轴器类似,爪式联轴器不需要润滑。
该联轴器由两个轮毂组成,这些轮毂具有相互啮合的钳口,可安装在弹性星形齿轮中。卡盘通常由铜合金、聚氨酯、Hyrtel或NBR制成,负责扭矩传递。
由于卡盘的弹性特性,它适用于传递冲击载荷。它还可以很好地抑制反作用力和振动。
工程师在压缩机、鼓风机、搅拌器和泵等应用中使用颚式联轴器。
梁式联轴器
梁式联轴器是一种机械加工的联轴器,在平行、轴向和角度偏差方面具有很高的灵活性。它是最好的低功率传输耦合器之一。
梁式联轴器具有带螺旋切口的圆柱形结构。这些切割的属性,如领先优势和启动次数,可以进行修改,以提供不同程度的错位能力。事实上,工程师可以在不牺牲结构完整性的情况下进行这些更改,因为它是由单个部件组成的。因此,梁耦合的第二个名称是螺旋耦合。
从本质上讲,梁联轴器实际上是弯曲的柔性梁。它们有单梁和多梁两种版本。多梁联轴器可以处理比单梁联轴器更大的平行错位。
梁式联轴器更适合低负载应用,因为扭转卷绕可能是一个真正的问题。因此,它被用于伺服电机和机器人的运动控制。
液力耦合器
液力耦合器是一种特殊类型,它使用液压流体将扭矩从一个轴传递到另一个轴。
联轴器由连接到主动轴的叶轮和连接到从动轴的转轮组成。整个装置固定在一个外壳中,也称为外壳。
当驱动轴旋转时,叶轮使流体加速,然后流体与转轮叶片接触。然后,流体将其机械能传递到转轮,并以低速离开叶片。
液力耦合器用于汽车变速器、船舶推进、机车和一些具有恒定循环载荷的工业应用。
用于选择的参数
联轴器是运动控制和动力传动系统的组成部分。它们提供了令人难以置信的优势,并在正确应用时解决了许多组装和服务环境问题。
要做到这一点,设计师必须考虑许多因素才能做出正确的选择。了解它们有助于减少耦合故障的实例并提高系统功能。这些因素包括:
- 扭矩水平
- 对齐限制
- 转速
- 润滑限制
扭矩水平
大多数制造商使用额定扭矩作为联轴器分类的基础。扭矩值取决于联轴器是用于运动控制还是用于动力传动应用。与后者相比,前者具有更低的扭矩和负载。了解应用中的预期扭矩水平将缩小正确联轴器的选择范围。
对齐限制
不同的应用具有不同的对齐需求。类似地,一些联轴器只能适应一种类型的不对中,而其他联轴器可以处理多种类型。
制造商还提到了每个联轴器不同类型不对准的不对准限制。这种考虑有助于进一步缩小搜索范围,并将正确的联轴器与正确的机器配对。
最大转速
每个联轴器也有一个最大允许转速。此限值也适用于联轴器。通用联轴器不能用于高转速应用。高转速联轴器需要静态和动态平衡,以确保安全、平稳和无噪音的服务。
这种平衡的设计是通过精确的机械加工和适当的紧固件分布而产生的。使用预期的RPM作为衡量标准可以帮助正确选择联轴器。
润滑限制
有时,使用条件可能会阻止需要的联轴器频繁重新润滑。另一方面,一些联轴器的设计在其整个使用寿命内不需要任何润滑。
如果扭矩要求较低,也可以使用传统联轴器的改进型。这些版本配有金属对金属润滑或金属和塑料组合,完全消除了润滑。设计者必须通过评估使用条件和应用需求来做出正确的联轴器选择。
- 9 次浏览
【软件工程】软件工程中的耦合
QQ群
视频号
微信
微信公众号
知识星球
软件工程中的耦合导论
软件工程中的耦合是软件需求规范(SRS)文档的一部分。它定义了每个软件模块与其他模块的依赖性和独立性因素。它可以作为模块之间相互依赖性的指标。耦合值越低,软件的质量就越高。名称耦合适用于此过程,因为它通常一次在两个模块之间进行审议。耦合过程的第一步是评估两个模块之间的关联,并定义模块中的功能依赖区域。

耦合类型
任何两个模块之间的耦合都可以通过模块与其他模块共享的资源的数量和类型来识别。该资源可以是功能行为、公共接口、用户界面中的公共字段、从字段中提取并在两个模块之间共享的数据、两个模块间共享的事务等。基于这些可能的依赖关系,软件工程中的耦合分为六种不同类型:
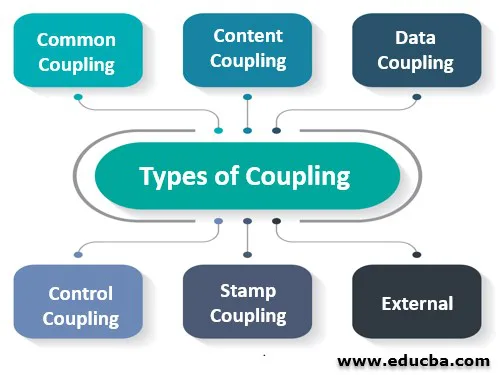
- 普通耦合
- 内容耦合
- 数据耦合
- 控制耦合
- 印记耦合
- 外部耦合
每一个软件需求规范文档过程都应该对依赖模块之间的耦合进行分类,无论哪一个在客户对需求进行简短评估后适用。
1.普通耦合
普通耦合由在任意两个软件系统模块中间共享总体约束的模块组成。这也可能是一个迹象,表明在公共约束中所做的任何更改都将反映在共享公共耦合场景的模块中。与任何其他过程一样,这种常见的耦合也为表征过程中涉及的优点和缺点提供了空间。人们应该避免这种类型的依赖,因为它需要更多的维护活动和更少的模块控制。这种耦合的一个很好的例子是登录页面,登录和后端模块是相互依赖的,因为登录验证在登录页面和后端数据库级别进行。
2.内容耦合
顾名思义,内容耦合是指两个模块共享其内容,当一个模块发生更改时,另一个模块也需要更新。当模块不同步时,会导致更高级别的功能不当行为。例如,当两个模块共享相同的数据时,两个模块数据库的主键列应该是相关的。否则由于依赖关系,模块的内容将反映不同步的数据。
3.数据耦合
当两个软件系统模块之间只有一种类型的交互,并且这种交互是以数据的形式时,就会发生数据耦合。除了数据形式之外,模块没有其他常见的共享资源,如功能或其他系统组件。数据耦合的一个例子是,两个用户接口(UI)在类似模块1的方面共享数据,将用于处理的数据传递给模块2,并从模块2接收回处理后的数据。尽管所有的耦合都需要最小化,但这种类型的耦合是可以容忍的,因为它不会影响软件的任何其他功能行为。
4.控制耦合
控制耦合是软件的功能流,其中两个软件模块通过提供涉及模块功能活动的共享控制来实现网络连接。这种类型的耦合对软件应用程序的影响可以是积极的,也可以是消极的,因为它只能根据所述模块共享的控制类型来定义。当功能被允许重用时,它被视为一个积极的影响。当参数在代码的功能部分中的多个位置重用时,通常会在代码级别观察到这种类型的耦合。
5.印记耦合
印记耦合发生在共享已结构化复杂数据集编译的任何两个模块之间。由于数据和元素是预先组织好并放置好的,因此两个耦合模块之间不会共享垃圾或未使用的数据。这有助于提高软件的总体效率及其性能。同时,系统设计者应该知道在多大程度上可以允许印记耦合的限制。
6.外部耦合
外部耦合可以描述为模块与常见外部影响因素相互关联的情况。它们可以是:
- 向两个模块发送相同数据或内容集的外部遗留应用程序
- 两个模块通用的硬件要求
- 两个模块都在使用的公用文件/文件夹
- 当两者在网络中使用相同的交换机/路由器进行通信时
耦合在软件工程中的优势
在软件工程过程中,作为软件开发生命周期的一部分,设计阶段将“耦合”作为其重要步骤之一。
以下是执行耦合过程的主要优点:
- 帮助识别中每个模块与其他模块的依赖关系
- 主要用于提高软件应用程序的质量和性能,因为分析有助于保持与
- 耦合支持功能
- 当模块之间的依赖性较低时,在一个单元中所做的更改不会影响
- 为更好的维护方法提供空间
结论
软件工程中的耦合是一个至关重要的过程,因为它在识别和限制软件各个模块之间的连接方面具有重要意义。此外,通过检查软件中所有元素之间的链接,耦合在将软件系统的质量和性能保持在最大水平方面发挥着重要作用。
- 5 次浏览
【软件设计】BDD由内而外采用策略
有一个明显但被忽视的采用BDD的策略非常出色。
一个被广泛采用的BDD可以带来不同。这只是分享同一个例子的问题,在软件开发的三个主要角色上有相同的共识。这会带来不同,因为你减少了误解、重复和无用的功能。它之所以有效,是因为它专注于做正确的功能,而不是做正确的功能。
经典的BDD采用策略
经典的策略是教三个主要角色通过小黄瓜进行协作。业务人员学习编写场景,开发人员将其转换为代码,QA验证它们。但在这种采用中有一个共同的问题:Gherkin是一种编程语言,企业不知道如何编写代码。
开始写小黄瓜有一个次要的影响:开发者通常认为商业是一个无可争议的权威。因此,开发人员没有勇气帮助企业修复场景。QA在这方面取得了更大的成功,因为他们把小黄瓜视为质量测试,他们对质量有最终决定权。
这就是问题所在。开发人员是唯一能够正确处理编程语言的人,他们太忙,太害怕,无法提前采用。因此,采用失败,并以两种可能性之一告终:BDD停止,或BDD继续处于次优状态,永远无法充分发挥其潜力。
由内而外的BDD采用策略。
这种策略是如此明显,以至于我不知道我们怎么都没有注意到它。
BDD是开发人员的需求,而不是业务,也不是QA。开发人员创建它是为了满足它的需求,然后它传播开来。BDD在开发者手中太强大了,以至于它一直在增长和传播,直到今天。那么,为什么不复制这种策略呢?
由内而外的BDD采用策略是模仿BDD本身的创建,但速度更快。它是由内而外的,因为它从开发人员开始,并通过业务和QA展开。在这个策略中,BDD不是传授的东西,而是希望的东西。
要了解这项工作的原因,我们需要了解开发人员在日常工作中面临的问题。开发人员收到用模糊语言编写的指令,他们必须进行解释和实现。一旦他们完成了,QA就会审查他们的工作。QA增加了自己的标准,QA可能会提出不同的需求和要求。开发人员正在进行猜测和重做。
BDD可以作为一种工具呈现给开发人员,以避免猜测和重复。在任何工作之前,如果有不清楚的地方,开发人员可以正确地编写小黄瓜场景。他们会把它作为一个商业例子,因为它读起来像英语,他们会有明确的回应。QA也是一样,如果他们认为在任何可能引起讨论的边缘情况下,他们可以在编写代码之前编写场景,然后询问QA。对于开发者来说,小黄瓜成了解决疑问和避免重复的工具。
后来,随着小黄瓜的来来往往,企业会了解小黄瓜以及它们如何影响产品行为。他们学到了一些只有通过实践才能学到的东西。QA也是如此。这两个角色都是在开发人员的日常实践中开始学习的,所以最终,所有人都会齐心协力。
原文:https://drpicox.medium.com/bdd-inside-out-adoption-strategy-f7bbfed94485
本文:
- 22 次浏览
【软件设计】TypeScript 中的 SOLID 原则
了解有关 TypeScript 中 SOLID 原则的更多信息
TypeScript 对用 JavaScript 编写干净的代码产生了巨大的影响。 但总有改进的方法,编写更好、更简洁的代码的一个重要方法是遵循由 Robert C. Martin(也称为 Uncle Bob)发明的所谓 SOLID 设计原则。
在本文中,我将通过使用 TypeScript 编写的示例向您介绍这些原则。 我已经在这个 Github 存储库上部署了所有示例。
单一职责原则 (SRP)
“一个类改变的原因不应该超过一个。”
一个类应该有一个目的/责任,因此只有一个改变的理由。 遵循这一原则可以更好地维护代码并最大限度地减少潜在的副作用。
在以下不好的示例中,您会看到如何存在多重责任。 首先,我们为一本书建模,而且,我们将这本书保存为一个文件。 我们在这里遇到了两个目的:
class Book {
public title: string;
public author: string;
public description: string;
public pages: number;
// constructor and other methods
public saveToFile(): void {
// some fs.write method to save book to file
}
}
第二个示例向您展示了如何通过遵循单一职责原则来处理这个问题。 我们最终有两个类,而不是只有一个类。 每个目的一个。
class Book {
public title: string;
public author: string;
public description: string;
public pages: number;
// constructor and other methods
}
class Persistence {
public saveToFile(book: Book): void {
// some fs.write method to save book to file
}
}
开闭原则 (OCP)
“软件实体……应该对扩展开放,但对修改关闭。”
与其重写你的类,不如扩展它。 通过不接触旧代码的新功能应该很容易扩展代码。 例如,实现一个接口或类在这里非常有帮助。
在下一个示例中,您将看到错误的操作方式。 我们使用了名为 AreaCalculator 的第三个类来计算 Rectangle 和 Circle 类的面积。 想象一下我们稍后会添加另一个形状,这意味着我们需要创建一个新类,在这种情况下,我们还需要修改 AreaCalculator 类以计算新类的面积。 这违反了开闭原则。
我们来看一下:
class Rectangle {
public width: number;
public height: number;
constructor(width: number, height: number) {
this.width = width;
this.height = height;
}
}
class Circle {
public radius: number;
constructor(radius: number) {
this.radius = radius;
}
}
class AreaCalculator {
public calculateRectangleArea(rectangle: Rectangle): number {
return rectangle.width * rectangle.height;
}
public calculateCircleArea(circle: Circle): number {
return Math.PI * (circle.radius * circle.radius);
}
}
那么,我们可以做些什么来改进这段代码呢? 为了遵循开闭原则,我们只需添加一个名为 Shape 的接口,因此每个形状类(矩形、圆形等)都可以通过实现它来依赖该接口。 这样,我们可以将 AreaCalculator 类简化为一个带参数的函数,而这个参数是基于我们刚刚创建的接口。
interface Shape {
calculateArea(): number;
}
class Rectangle implements Shape {
public width: number;
public height: number;
constructor(width: number, height: number) {
this.width = width;
this.height = height;
}
public calculateArea(): number {
return this.width * this.height;
}
}
class Circle implements Shape {
public radius: number;
constructor(radius: number) {
this.radius = radius;
}
public calculateArea(): number {
return Math.PI * (this.radius * this.radius);
}
}
class AreaCalculator {
public calculateArea(shape: Shape): number {
return shape.calculateArea();
}
}
里氏替换原则 (LSP)
“使用指向基类的指针或引用的函数必须能够在不知情的情况下使用派生类的对象。”
使用指向上层类的指针或引用的下层类必须能够在不知情的情况下使用派生类的对象。 这些低级类应该只是扩展上级类,而不是改变它。
那么我们在下一个坏例子中看到了什么? 我们上了两节课。 Square 类扩展了 Rectangle 类。 但正如我们所见,这个扩展没有任何意义,因为我们通过覆盖属性宽度和高度来改变逻辑。
class Rectangle {
public width: number;
public height: number;
constructor(width: number, height: number) {
this.width = width;
this.height = height;
}
public calculateArea(): number {
return this.width * this.height;
}
}
class Square extends Rectangle {
public _width: number;
public _height: number;
constructor(width: number, height: number) {
super(width, height);
this._width = width;
this._height = height;
}
}
因此,我们不需要覆盖,而是简单地删除 Square 类并将其逻辑带到 Rectangle 类而不改变其用途。
class Rectangle {
public width: number;
public height: number;
constructor(width: number, height: number) {
this.width = width;
this.height = height;
}
public calculateArea(): number {
return this.width * this.height;
}
public isSquare(): boolean {
return this.width === this.height;
}
}
接口隔离原则
“许多特定于客户端的接口都比一个通用接口好。”
简单地说,更多的接口总比接口少的好。 让我解释下一个不好的例子。
我们有一个名为 Troll 的类,它实现了一个名为 Character 的接口。 但是由于我们的巨魔既不会游泳也不会说话,这个角色界面似乎不适合我们的类。
interface Character {
shoot(): void;
swim(): void;
talk(): void;
dance(): void;
}
class Troll implements Character {
public shoot(): void {
// some method
}
public swim(): void {
// a troll can't swim
}
public talk(): void {
// a troll can't talk
}
public dance(): void {
// some method
}
}
那么我们可以通过遵循这个特定的原则来做些什么呢? 我们删除了 Character 接口并将其功能拆分为四个接口,并且仅将我们的 Troll 类依赖于我们实际需要的这些接口。
interface Talker {
talk(): void;
}
interface Shooter {
shoot(): void;
}
interface Swimmer {
swim(): void;
}
interface Dancer {
dance(): void;
}
class Troll implements Shooter, Dancer {
public shoot(): void {
// some method
}
public dance(): void {
// some method
}
}
依赖倒置原则(DIP)
“取决于抽象,[不是]具体。”
这到底是什么意思,对吧? 嗯,其实很简单。 让我们揭开它的神秘面纱!
在这个糟糕的例子中,我们有一个 SoftwareProject 类,它初始化 FrontendDeveloper 和 BackendDeveloper 类。 但这是错误的方式,因为这两个类彼此非常相似,我的意思是,它们应该做类似的事情。 因此,为了实现依赖倒置原则的目标,有更好的方法来满足需求。
class FrontendDeveloper {
public writeHtmlCode(): void {
// some method
}
}
class BackendDeveloper {
public writeTypeScriptCode(): void {
// some method
}
}
class SoftwareProject {
public frontendDeveloper: FrontendDeveloper;
public backendDeveloper: BackendDeveloper;
constructor() {
this.frontendDeveloper = new FrontendDeveloper();
this.backendDeveloper = new BackendDeveloper();
}
public createProject(): void {
this.frontendDeveloper.writeHtmlCode();
this.backendDeveloper.writeTypeScriptCode();
}
}
那么我们该怎么办呢? 正如我所说,它实际上非常简单,而且更容易,因为我们之前已经学习了所有其他原则。
首先,我们创建一个名为 Developer 的接口,由于 FrontendDeveloper 和 BackendDeveloper 是相似的类,我们依赖于 Developer 接口。
我们不是在 SoftwareProject 类中以单一方式初始化 FrontendDeveloper 和 BackendDeveloper,而是将它们作为一个列表来遍历它们,以便调用每个 develop() 方法。
interface Developer {
develop(): void;
}
class FrontendDeveloper implements Developer {
public develop(): void {
this.writeHtmlCode();
}
private writeHtmlCode(): void {
// some method
}
}
class BackendDeveloper implements Developer {
public develop(): void {
this.writeTypeScriptCode();
}
private writeTypeScriptCode(): void {
// some method
}
}
class SoftwareProject {
public developers: Developer[];
public createProject(): void {
this.developers.forEach((developer: Developer) => {
developer.develop();
});
}
}
感谢您阅读我关于 Medium 的第一篇文章。 我希望,我已经能够刷新你的知识。 您可以在 Wikipedia 上阅读有关 SOLID 的更多信息。
原文:https://blog.bitsrc.io/solid-principles-in-typescript-153e6923ffdb
- 33 次浏览
【软件设计】UML中关联,聚合和组合区别
考虑以下对象类之间的差异和相似之处:宠物、狗、尾巴、主人。

我们可以看到以下关系:
- 主人喂宠物,宠物感谢主人(关联)
- 尾巴是狗和猫的一部分(聚集/组成)
- 猫是一种宠物(遗传/概括)
下图显示了三种类型的关联连接器:关联、聚合和组合。我们将在这个UML指南中复习它们。



下图显示了一个概括。我们将在稍后的UML指南中讨论它。

关联
如果一个模型中的两个类需要彼此通信,那么它们之间必须有一个链接,并且可以通过一个关联(连接器)来表示。
关联可以用这些类之间的一条线表示,该线带有指示导航方向的箭头。如果两边都有箭头,则这种关联称为双向关联。
我们可以通过在表示关联的行中添加多重装饰来表示关联的多重性。该示例表明,一个学生有一个或多个导师:
一个学生可以与多个老师关联:

这个例子表明每个老师都有一个或多个学生:
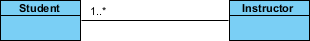
我们还可以使用角色名指示关联中对象的行为(例如,对象的角色)。
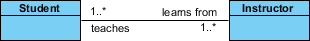
关联vs聚合vs组合
“关联、聚合和组合之间的区别是什么”这个问题最近经常被问到。
聚合和组合是关联的子集,意味着它们是特定的关联案例。在聚合和组合中,一个类的对象“拥有”另一个类的对象。但有一个微妙的区别:
- 聚合意味着子组件可以独立于父组件而存在。示例:类(父类)和学生(子类)。删除类,学生仍然存在。
- 组合意味着子元素不能独立于父元素而存在的关系。例子:房子(父母)和房间(孩子)。房间不能与房子分开。
组合的例子:
除了类A和类B之间的部分关系之外,我们还应该更具体地使用composition链接——这两个类之间存在很强的生命周期依赖关系,也就是说,当类A被删除时,类B也会被删除

聚合的例子:
值得注意的是,聚合链接没有以任何方式声明类A拥有类B,也没有声明两者之间存在父子关系(当父类删除时,其所有的子类也因此被删除)。事实上,恰恰相反!聚合链接通常用于强调类A实例不是类B实例的独占容器,因为实际上同一个类B实例拥有另一个容器/s。

加起来-
总而言之,关联是一个非常通用的术语,用于表示一个类使用另一个类提供的功能时的情况。如果一个父类对象拥有另一个子类对象,并且如果没有父类对象,这个子类对象就不能有意义地存在,那么我们称它为复合。如果可以,就称为聚合。
泛化和专业化
泛化是一种机制,用于将类似的对象类组合成一个更一般化的类。泛化标识一组实体之间的共性。共性可以是属性、行为,或者两者都有。换句话说,超类拥有最通用的属性、操作和可以与子类共享的关系。子类可能有更专门化的属性和操作。
专门化是泛化的反向过程,泛化意味着从现有的类创建新的子类。
例如,银行账户有两种类型——储蓄账户和信用卡账户。储蓄账户和信用卡账户从银行账户中继承了常见的/广义的属性,比如账户号、账户余额等,也有它们特有的属性,比如未结算的付款等。

泛化和继承
泛化是我们用来在UML中表示将公共属性抽象为基类的术语。UML图的泛化关联也称为继承。当我们在编程语言中实现泛化时,它通常被称为继承。泛化和继承是相同的。这些术语只是根据使用的上下文而有所不同。
原文:https://www.visual-paradigm.com/guide/uml-unified-modeling-language/uml-aggregation-vs-composition/
本文:http://jiagoushi.pro/node/1213
讨论:请加入知识星球【首席架构师圈】或者微信【jiagoushi_pro】或者QQ群【11107777】
- 297 次浏览
【软件设计】紧耦合和松耦合之间有什么区别?
QQ群
视频号
微信
微信公众号
知识星球
紧密耦合和松散耦合都在软件开发中占有一席之地。我们讨论了每种方法的优缺点,以及何时采用它们是正确的。
紧耦合和松耦合是用于描述应用程序组件之间关系的术语。在紧密耦合中,系统的组件高度依赖于彼此。如果一个组件发生故障,它也会影响其他组件,并最终导致整个系统瘫痪。这造成了灵活性问题,因为对一个组件的任何修改都可能需要对其他组件进行修改。这会使系统难以扩展和维护。
在一个松散耦合的系统中,组件是相互独立的。每个组件都有自己定义良好的接口,并通过标准化协议与其他组件进行通信。对一个组件的更改不需要对其他组件进行更改,从而使系统更加灵活和易于维护。这里唯一需要注意的是处理多个资源的复杂性增加,尤其是对于大型应用程序。随着微服务、容器和API等现代技术的兴起,松耦合越来越流行。
让我们通过探索每个概念的工作原理来深入研究这些概念。
紧密耦合的工作原理

Architecture diagram showing loosely coupled pieces
紧密耦合一直是构建应用程序的标准方式,直到2010年代中期,单页应用程序才开始流行起来。紧密耦合是单片架构的代名词,其中所有组件都被捆绑到一个可部署的单元中。
紧密耦合系统的特点是组件之间高度相互依赖,这使得很难在不影响其他组件的情况下更换或修改一个组件。
例如,考虑一个具有数据库、用户界面(UI)和业务逻辑组件的软件系统。在紧密耦合的系统中,业务逻辑组件可以直接访问数据库和用户接口组件。紧密耦合意味着对数据库或UI所做的任何更改都可能给业务逻辑组件带来错误。
紧密耦合的优点
单片架构和组件之间的紧密耦合是更多新软件的必备条件。它最初的构建和维护更简单。由于大多数新应用程序都希望“快速失败”,因此这种方法是有意义的。
紧密耦合还有其他几个优点,使其在某些情况下成为理想的解决方案:
更快的开发
构建一个紧密耦合的系统更容易、更快,因为它比松散耦合需要更少的资源和时间。这可以实现快速原型设计和迭代,这在速度优先的情况下是有益的。
加强对系统的控制
紧密耦合可以对系统的行为提供更多的控制,因为组件之间的相互依赖性是众所周知的。这使得预测系统在不同条件下的行为更加容易。
此外,良好的控制使整个系统更容易实现一致性。由于所有组件都是紧密集成的,因此可以确保它们都遵循相同的规则和标准。在需要严格遵守标准或法规的情况下,这一点尤为重要。
高性能
尽管使整个系统难以扩展,但组件之间的高度相互依赖性允许组件之间更高效的通信,而不需要额外的抽象层或通信协议。这可以减少开销并提高性能,尤其是在高吞吐量或低延迟非常重要的情况下。
维护更简单
紧密耦合的应用程序不需要考虑维护,以确保前端和后端传递正确的数据和功能。由于它们是同一代码库的一部分,因此这是应用程序固有的。相比之下,具有通过API通信的前端和后端的去耦应用程序都需要维护,两者之间的连接也需要持续关注。
紧耦合的缺点
在软件开发中,很少有一种方法对所有情况都是“最好的”。总有取舍。这些都是紧耦合的缺点。
可能难以扩展
紧密耦合的系统可能很难扩展,因为添加新组件或增加现有组件的大小可能需要对系统的其他部分进行重大更改。
代码重复
紧密耦合的系统可能比松散耦合的系统具有更多的代码复制,因为组件需要更频繁地相互通信。随着时间的推移,维护和更新系统会变得更加困难。
高度依赖性
紧密耦合的系统是高度相互依赖的,因为它们的组件是相互连接的。因此,对中一个组件的更改可能需要对其他组件进行更改,从而很难在不造成意外后果的情况下修改系统。这可能导致缺乏灵活性,使其更难响应不断变化的需求或不断发展的业务需求。
高度协调
规模和复杂性不断增长的紧密耦合系统最终需要开发人员之间的高度协调,以确保对一个组件所做的更改不会对其他组件产生负面影响。
通常会发生的情况,尤其是对于从资金不足的MVP发展而来的应用程序,是在没有适当文档或代码标准的情况下构建应用程序的新部分。像
松耦合的工作原理
松耦合是软件工程中的一种设计模式,涉及减少系统中组件之间的相互依赖性。在松耦合系统中,每个组件都被设计为独立于其他组件运行,对共享资源或通信协议的依赖最小。
在高层,松耦合系统通过使用标准化接口来工作,以允许组件以灵活和模块化的方式相互通信。每个组件负责自己的行为和状态,并使用定义良好的API或其他形式的标准化通信与其他组件进行通信。
实现松耦合的一种常见方法是使用消息传递体系结构,其中组件通过中央消息代理或其他中介发送消息来相互通信。这可以允许组件以解耦的方式进行通信,而不依赖于直接连接或共享资源。
松耦合的另一种方法是使用微服务架构,这涉及到将一个较大的系统分解为较小的、可独立部署的服务,这些服务使用标准化的API或协议相互通信。
松耦合的特点
以下是松耦合系统的一些关键特征:
模块性
松散耦合通常涉及将系统分解为更小、可独立部署的模块,这些模块可以单独开发和维护。这使得管理系统的复杂性变得更容易,因为开发人员可以专注于开发和维护单个模块,而不必担心它们如何适应更大的系统。它还允许在开发和部署方面具有更大的灵活性,因为可以在不影响系统其余部分的情况下更新或更换单个模块。
此外,模块化还可以促进代码重用,因为单个模块可以设计用于系统的多个部分,甚至可以完全用于不同的系统。这可以带来更高效的开发过程,并降低系统中出现错误或bug的风险。
标准化接口
为了与系统中的其他组件通信,松耦合系统中的每个模块通常使用标准化接口,如RESTful API或消息代理。这允许在不影响系统中其他组件的情况下添加、删除或更换组件,只要它们符合相同的接口标准。
标准化接口也促进了不同系统或组件之间的互操作性。例如,如果两个系统使用相同的接口进行通信,它们可以轻松地交换数据或功能,而不需要大量的自定义集成工作。
解耦通信
解耦通信是松耦合系统的另一个重要特征。在松耦合系统中,组件之间的通信通常被设计为异步和解耦的,这意味着组件可以相互通信,而无需了解彼此的具体实现细节或内部工作。
这通常是通过使用消息传递系统或事件驱动架构来实现的,其中组件将事件或消息发布到中央集线器或消息代理,而其他组件可以订阅这些事件或消息并相应地做出响应。
例如,考虑一个由多个组件组成的物流应用程序,包括发货跟踪系统、仓库管理系统和交付管理系统。在紧密耦合的系统中,这些组件可以紧密集成,要求每个组件都知道其他组件的具体实现细节。
可扩展性
通过根据需要添加额外的模块或服务,松耦合可以更容易地水平扩展系统。
例如,考虑一个基于web的电子商务应用程序,它由多个组件组成,包括web服务器、数据库服务器和支付网关。在紧密耦合的系统中,这些组件可能会紧密集成,从而难以独立扩展。然而,在松散耦合的系统中,每个组件都可以根据其特定需求进行独立缩放。
例如,如果数据库服务器正经历高流量,则可以向数据库服务器添加额外的资源以处理增加的负载,而不会影响网络服务器或支付网关。类似地,如果支付网关需要处理大量交易,则可以向支付网关添加额外的资源,而不会影响其他组件。
松耦合的优点
在软件设计中使用松耦合的一些优点包括:
互操作性
松耦合可以使集成不同的系统或组件变得更容易,因为每个组件都可以设计为使用标准化接口或API与其他组件通信。
维护不那么复杂
松耦合可以通过减少对一个组件的更改对其他组件的影响来提高可维护性。这样可以更容易地隔离和修复错误、添加新功能或对系统进行其他修改,而不会对系统的其他部分造成意外后果。
然而,这也意味着更多的维护,因为需要维护组件及其连接方式。
性价比高的
松耦合更具成本效益,因为它减少了对昂贵的系统范围升级或重写的需求。相反,企业可以根据需要对单个组件进行增量更改,这比进行系统范围的更改成本更低,破坏性更小。
敏捷性
松耦合可以通过允许企业快速轻松地对其软件系统进行更改来提高灵活性,以响应不断变化的业务需求或市场条件。这可以帮助企业在竞争中保持领先地位,并更有效地应对不断变化的客户需求。
常见问题
Q: 紧耦合和松耦合有什么区别?
A: 紧密耦合是指两个或多个软件组件紧密连接并相互依赖以正常工作的情况。另一方面,松耦合意味着组件之间的相互依赖性较小,可以更独立地运行。
Q: 紧耦合和松耦合哪个更好?
A: 与软件开发中的其他一切一样,没有一种方法是“更好的”。通常,松耦合更适合于更大或更复杂的系统,其中灵活性、可扩展性和可维护性更重要,而紧耦合更适合更简单的系统,其目标是保持较低的复杂性。
Q: 有可能从一个紧密耦合的系统转移到一个松散耦合的系统吗?
是的,从紧密耦合的系统转移到松散耦合的系统是可能的,尽管这可能需要大量的精力和资源。这可能涉及重构现有代码、重新设计系统架构以及实现新的通信协议和接口。更松散耦合的系统的好处,例如更大的灵活性和可扩展性,可能会使这项工作变得值得。
关键要点
软件组件之间的耦合程度对系统的灵活性、可扩展性和可维护性有着重大影响。虽然紧密耦合可以提供某些优势,如性能和控制,但更松散耦合的体系结构更适合现代软件开发,并可以提供模块化、标准化接口和解耦通信等好处。也就是说,选择正确的耦合级别取决于相关系统的特定需求和要求。
- 133 次浏览
【软件设计】紧耦合和松耦合的区别
QQ群
视频号
微信
微信公众号
知识星球
许多现代编程趋势,如微服务、容器和API,都有强烈的松耦合感。换句话说,服务现在被设计为可重复使用和可互换,而不会破坏现有的互连。几年来,软件行业一直在远离涉及紧密耦合的自定义集成。但是这些术语到底是什么意思呢?今天,我们将从一般的计算机编程角度定义什么是松散耦合和紧密耦合,并探讨这些范式对web API设计和实现意味着什么。
紧密耦合的组件是为了满足单一目的而构建的,它们相互依赖,并且不容易重复使用。
什么是耦合?
从广义上讲,连接的软件服务要么更紧密地耦合,要么更松散地耦合。紧密耦合是将资源绑定到特定目的和功能的概念。紧密耦合的组件可以将每个资源绑定到特定用例、特定接口或特定前端。
本质上,一个紧密耦合的系统是专门构建的,每一个偏离标准的定制都有其自身的资源和集成。这是建立数据关系的一种简单方法,在理解、依赖和交互所述信息方面是有益的。然而,紧密耦合给软件的可扩展性和可扩展性带来了明显的损失。
然而,松散耦合是相反的范式。在一个松散耦合的系统中,组件是相互分离的。每个资源都可以有多个前端或应用程序。这些元素中的每一个都是相反的。所有系统都可以独立工作,作为较大系统组的一部分,也可以与多个分段系统组紧密配合。最终,任何东西都不会被迫与其他任何东西建立关系,这在可扩展性和可扩展性方面带来了明显的好处。需要注意的是,总体复杂性往往会增加。
以无头CMS为例说明松耦合。无头CMS将后端与前端分离,这意味着开发人员可以从任何客户端浏览器、平台或设备重复使用并与相同的启用API的后端交互。
松耦合作为最佳实践
解耦或松耦合的组件更加独立和可重用,从而提高了整体可扩展性。
松耦合和紧耦合是相当普遍的概念。那么,在实践中,哪些用例可以从每种方法中受益呢?
在我们讨论紧密耦合之前,应该注意的是,松散耦合是迄今为止RESTful API开发最理想的范式。RESTful API应该能够在多个资源中从一个用例转换、重新混合、扩展和变形到另一个用例。从本质上讲,一个合适的REST实现应该是分层的和无状态的——它应该在很大程度上独立于单个用例存在,并且应该用接口处理所有请求所需的所有信息来响应。
即使在真实RESTful设计的需求之外,松散耦合也是大多数现代用例的优秀实现。任何API类型都应该需要最少的新工作来利用,允许开发人员在多个实现和接口中使用他们的知识。更少的自定义实现意味着在构建核心功能上花费更多的精力,而不是为每个新资源构建单独的应用程序和接口。
此外,松耦合带来了一些显著的安全性提升。由于每个资源不存在一百万个不同接口的一百万个不同版本,因此需要保护和更新的数据量可能会大大减少。实际上,松散耦合导致了一个更加安全的生态系统。
最后,智能组件和哑组件在很大程度上相互隔离,减少了过度获取。换句话说,需要更多知识或数据才能运行的智能组件可以通过与集中式API对话来实现。不需要知道太多的愚蠢组件可以独立运行,而不会与耦合的、独特的资源或需求发生冲突。
最终,松耦合会降低组件之间的相互依赖性,并降低破坏更改的风险。
紧耦合作为一种替代方案
如果松耦合有这么多好处,为什么还要考虑紧耦合?虽然紧耦合确实不是大多数微服务和RESTful设计的最佳选择,但它在特定的应用程序中确实有一席之地。
松耦合的主要好处是资源与接口解耦,以允许更多可互操作、可扩展的API和资源模式。然而,并不是所有的服务都需要这样。在某些情况下,一个人有一个单一的资源和一个单一类型的单一接口。在这种情况下,通用API通常与单个用例和单个工作流绑定。
松耦合还会给系统带来更大的复杂性。某些工作流仅使用一个设备、一个接口和一个API。如果只计划一个实现,那么紧密耦合可以使开发工作简单得多。除非应用程序很有可能会转向更通用的东西,否则简单性是首选。
非永久性耦合
虽然紧耦合和松耦合无疑是最明显的类型,但还有另一种类型的耦合。从技术上讲,非永久耦合是一种混合型耦合,不属于这两类。非永久耦合可以使用基于时间或位置的因素来耦合或解耦组件。在实践中,它仍然经常属于松散或紧密耦合的保护伞下,但这种行为足够独特,可以在这里单独定义。
时间耦合是指当另一个资源已经响应了初始请求时,资源只能由一个资源使用。资源和接口是完全解耦的,直到创建了一个有时间限制的耦合。虽然大多数情况下都应该避免这种情况,但在一些例子中这可能是有效的。例如,管理对工作空间的远程访问的安全应用程序可以使用时间耦合来限制对电梯连接API的访问,直到凭证服务授权请求用户为止。
与此相关的是位置耦合,这是一种将资源耦合到依赖于两者接近程度的接口的范例。例如,本地服务API可能与资源紧密耦合,例如要求某人在办公室,并通过已知和可信的机器访问以访问资源。在这种情况下,只有当用户接近地理上有边界的区域中的资源时,才会创建耦合。
松耦合和紧耦合实施
关于这两种范式在实践中如何工作的示例,可以在C#Corner中找到一个优秀的代码示例。我们在下面复制它以供评论。
让我们从一个简单的紧耦合情况开始。想象一下,我们正在用C#编写一个远程控制应用程序。以下代码表示这种情况:
namespace
TightCoupling
{
public class Remote
{
private Television Tv { get; set;}
protected Remote()
{
Tv = new Television();
}
static Remote()
{
_remoteController = new Remote();
}
static Remote _remoteController;
public static Remote Control
{
get
{
return _remoteController;
}
}
public void RunTv()
{
Tv.Start();
}
}
}
这种方法的明显好处是简单——在少数代码行中,我们就有了一个非常简单的远程控制器框架。也就是说,这种方法存在重大问题。通过将接口(遥控器)和资源(电视)紧密耦合,可以创建一种关系,在这种关系中,没有另一个,这两个元素中的任何一个都无法发挥作用。没有遥控器就无法更换电视,遥控器除了控制电视之外无法控制任何东西,任何一种更改都会直接影响另一种。如果电视和遥控器是这个生态系统中唯一的设备,这可能是可以接受的。然而,如果制造商想要更大的可扩展性来控制其他设备,那么在当前的方法中这是不可能的。
为了解决这个问题,让我们考虑一种更松散耦合的方法。以下代码是远程实例的远程类和管理类:
public interface IRemote
{
void Run();
}
public class Television : IRemote
{
protected Television()
{
}
static Television()
{
_television = new Television();
}
private static Television _television;
public static Television Instance
{
get
{
return _television;
}
}
public void Run()
{
Console.WriteLine("Television is started!");
}
}
public class Remote
{
IRemote _remote;
public Remote(IRemote remote)
{
_remote = remote;
}
public void Run()
{
_remote.Run();
}
}
这种方法需要一块代码用于实际使用,如下所示:
class Program
{
static void Main(string[] args)
{
Remote remote = new Remote(Television.Instance);
remote.Run();
Console.Read();
}
}
这里的主要缺点从一开始就很明显——代码比更直接的紧耦合方法要复杂得多。也就是说,它获得了一些显著的好处。
首先,它将可用性和可扩展性扩展到了一个更高的级别。通过将遥控器和电视相互抽象,可以添加、扩展和开发新的功能,而基本上不会对资源和接口产生影响。这本质上是将整个接口和数据流模块化,允许在许多不同的级别进行开发。
另一个主要的好处是,每个组件都可以单独进行测试和操作。在我们最初的紧密耦合范式中,我们的测试方法受到限制,因为我们只能检查整个数据流。随着一切模块化,我们可以测试每个单独的组件。
也许这里最大的好处是我们可以合并和扩展每个类。例如,让我们假设我们的遥控器不仅仅用于电视——我们可能想控制空调、智能扬声器或冰箱。如果我们使用IR或蓝牙模块,我们可能希望将所有命令输入到单个发射器函数中。虽然具体的命令显然会有所不同,但基本功能仍然相同。对于松散耦合的系统,这些功能可以组合成一个单一的接口,但它们本身可以是具有不同可扩展功能的不同代码集的一部分。
在紧密耦合的范式中,这些单独的功能中的每一个都需要针对特定的用例进行明确的开发,这几乎比仅仅在松散的范式中工作更复杂。
实践中的耦合示例
让我们考虑一些真实世界的例子,更好地了解紧耦合和松耦合之间的区别。紧密耦合的一个例子是经典的单片软件体系结构设计模式。尽管单片设计通常被认为是过时的,但它们确实有一些实际用途。例如,亚马逊Prime Video的开发人员最近分享了将他们的设计重构为一个更为单一的模式以降低成本和提高可扩展性的意义。
单片设计与微服务架构相反,在微服务架构中,组件更加独立和分布式。例如,Soundcloud花了数年时间打破其单一的基础设施,采用更解耦的、基于API的服务。微服务架构通常使用Kubernetes等云原生平台来管理分布式、基于容器的服务的部署和协调。
松散耦合还实现了现代网络安全不可或缺的关注点分离哲学。例如,实现API安全性是将尽可能多的安全功能外部化的最佳实践。现代OAuth流通常包含一个外部授权服务器,该服务器可以验证和发布JSON web令牌。以这种方式分离安全问题有助于支持最小权限访问模型。
最佳选择
通常,我们的建议是“这取决于……查看您的用例,然后决定每个选项是否合适。”然而,这是我们更直接的少数情况之一:紧密耦合几乎总是不适合RESTful API设计。解耦组件通常会带来更好的可扩展性,并有助于系统经得起未来考验。仅在极少数情况下(通常为非REST)才建议使用紧密耦合。在这种情况下,不要害怕使用紧耦合,而是要考虑你最初的假设是否正确。
你觉得耦合怎么样?这是对每种范式的优点和缺点的公平评估吗?请在下面的评论中告诉我们。
- 76 次浏览
【软件设计】让代码更可重用的4种方法
QQ群
视频号
微信
微信公众号
知识星球

可重用代码节省了时间、精力和成本,使其在软件开发中至关重要。
考虑以下4个基本属性,使您的代码更加可重用:
1——模块性

计划并确定软件中需要划分为块的部分。将一个软件系统划分为多个独立的模块,并使每个类/方法只做一件事。
模块化使代码易于理解和维护。它允许在程序中容易地重用方法或函数,并减少重复写入的需要。
以代码的简单性为目标,这样其他人就可以轻松地理解体系结构,并识别与代码重用相关的组件、边界和接口。
2-高内聚性

内聚性是两个或多个系统如何协同工作的程度。
方法或函数中的代码行需要协同工作以创建目标感。类的方法和属性必须协同工作才能定义类及其用途。类应该组合在一起以创建模块,这些模块一起工作以创建系统的体系结构。
通过保持高内聚性来保持代码的可重用性。这样可以确保您的代码能够工作并适应不同的环境,从而使其在项目中发挥作用。
3--松耦合

好的软件有松散的耦合。这意味着模块不受严格约束,可以独立运行,并且在出现错误时不会相互影响。
相对于模块化,使类/方法专注于单个函数。减少相互链接的类。它将更容易识别类,并使您的代码模块化与松散耦合。
当你的模块高度耦合时,很难修改一个函数,并且会倾向于要求程序员编辑整个代码库,而不仅仅是修改单个函数。
松耦合允许代码在没有外部支持的情况下执行某个功能,从而使代码更具可移植性。然而,零耦合的软件将无法运行,而那些耦合度非常低的软件将难以维护。当确实需要时,通过耦合模块来保持平衡。
4——测试类别/功能

为你的类编写一个单元测试,并使测试你的类变得容易。让每个测试用例方法只测试一个函数。不要试图同时测试太多不同的类。
测试方法/类将有助于确保可重用性。为了实现更简单、更干净、更快的实现,请考虑测试的每个函数或方法的独立先决条件集。
重用能力使从较小的组件构建更大的系统变得容易,同时能够识别这些部件的共性。
保持模块化、高内聚性和松耦合将有助于使代码更灵活地适应不同的项目,并易于扩展或修改,这对代码重用至关重要。
制作可重复使用的代码并不是为了开发过于通用和单一的全能代码。首先,您只需要确保您的代码解决了给定的问题,并满足其目的和用户需求。
专注于您需要提供的东西:功能和所需的性能。如果您努力编写一个简洁、实用且易于维护的简单代码单元,那么重用性自然会成为一种副产品。
- 11 次浏览
【软件设计】软件设计术语|耦合与内聚
QQ群
视频号
微信
微信公众号
知识星球
什么是内聚和耦合?
软件工程中的内聚和耦合是描述软件系统中模块或组件之间关系的两个重要概念。
它们用于评估设计质量,并测量系统组件之间的交互效果。
耦合表示模块之间的关系,内聚定义了模块内部的关系。
凝聚性
衔接是指单个模块的职责相关和集中的程度。
它衡量模块的内部元素连接的强度,以及为实现共同目的而协同工作的强度。
高内聚性提高了代码的可重用性、可维护性和可理解性。
内聚度越高,软件的质量就越好。
耦合
耦合是指系统中两个或多个模块之间的相互依赖程度。
它测量模块连接的紧密程度以及它们相互依赖的程度。
低耦合促进了代码的独立性、模块性和灵活性。
耦合度越低,软件的质量越好。
什么是凝聚力?
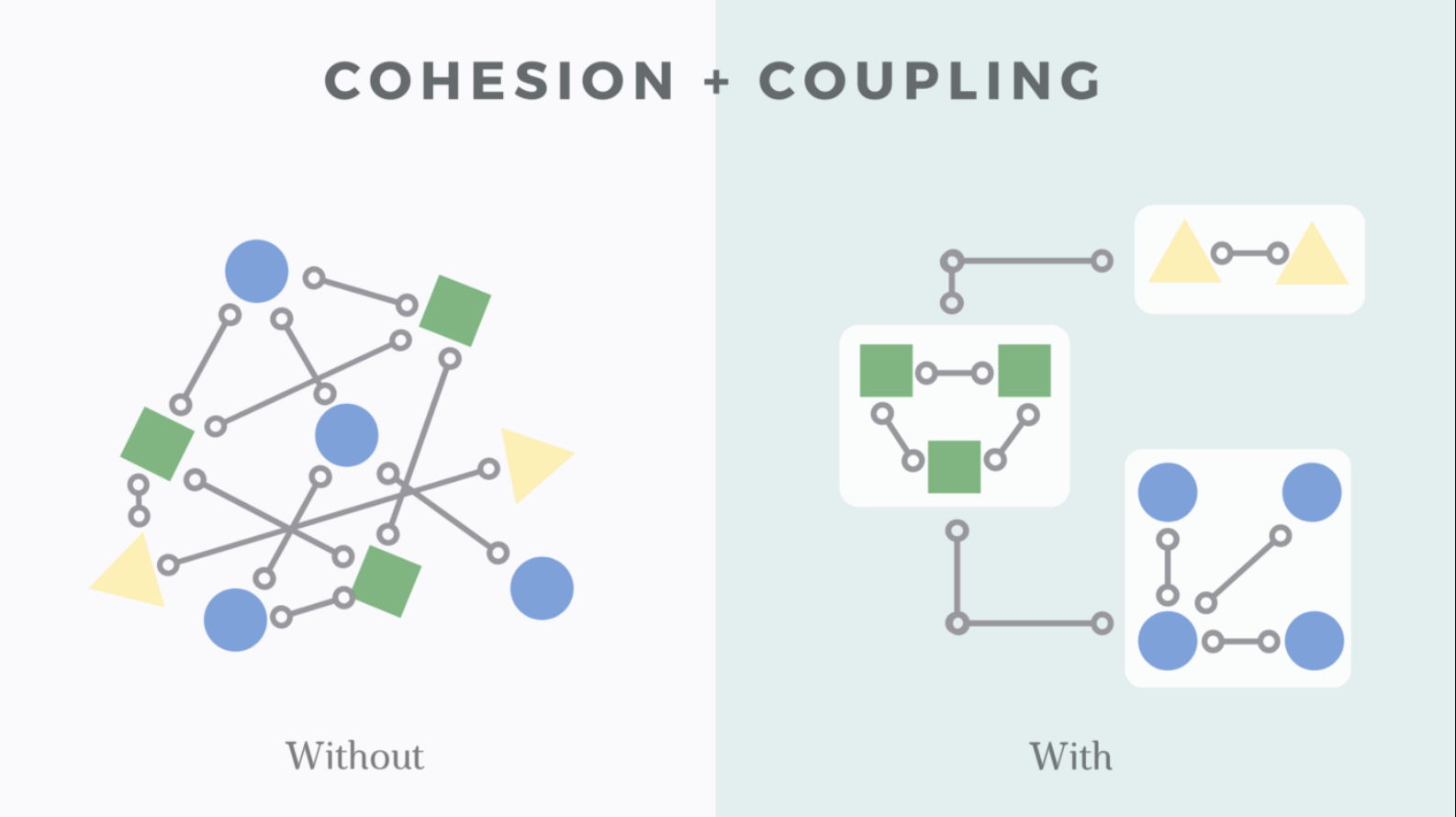
软件工程中的内聚性是指模块/组件内部的元素在多大程度上属于一起,用于执行单个任务。
简单地说,它是模块的元素在功能上相关的程度。
具有高度内聚性的模块包含彼此紧密相关并在其目的上统一的元素。
但是,如果一个模块包含不相关的元素,则称其具有低内聚性;如果该模块具有所有相关元素,则认为其具有高内聚性。
一个好的软件设计将具有很高的内聚性。
衔接的概念与单一责任原则密切相关,即一个班级只应承担一项责任或执行一项任务。
SRP之后的模块可能具有很高的内聚性,因为它们旨在执行软件中的单个任务。
软件工程中的内聚有哪些不同类型?
软件工程中的内聚类型有:

1.功能内聚
当模块中的元素执行单个定义明确的任务或功能时,就会发生功能内聚。
模块中的所有元素都有助于实现相同的目标。
这种类型的凝聚力被认为是最理想和最强的。
示例-读取交易记录、余弦角计算、航空公司乘客座位分配等
2.顺序内聚
当模块中的元素按特定顺序排列时,就会发生顺序衔接,其中一个元素的输出作为下一个元素。
这些元素以逐步的方式执行,以实现特定的功能。
示例-交叉验证记录和模块格式、原始记录使用、原始记录格式、原始纪录中字段的交叉验证等。
3.通讯内聚
当模块中的元素对相同的输入数据进行操作或通过参数共享数据时,就会发生通信衔接。
模块中的元素通过相互传递数据来协同工作。
它比顺序衔接弱。
示例-使用客户帐号、查找客户名称、客户的贷款余额等。
4.过程内聚
当模块中的元素基于特定的动作或步骤序列进行分组时,就会发生过程衔接。
这种类型的衔接比交际衔接弱。
示例-读取、写入、编辑模块、对数字字段进行零填充、返回记录等。
5.时间内聚
当模块中的元素在同一时间或同一时间段内执行时,就会发生时间内聚。
它被认为比程序衔接弱。
示例-将计数器设置为零,打开学生文件,清除错误消息的变量,初始化数组等。
6.逻辑内聚
当模块中的元素在逻辑上是相关的,但不适合任何其他内聚类型时,就会发生逻辑内聚。
它不像其他内聚类型那样强。
示例—组件从磁带、磁盘和网络等读取输入时。
7.重合衔接
当元素彼此不相关时,就会发生重合内聚。
示例-用于杂项功能、客户记录使用、客户记录显示、总销售额计算和读取交易记录等的模块。
什么是耦合?
软件工程中的耦合是指软件系统中模块或组件之间的相互依赖和连接程度。
如果两个模块紧密连接,则称其具有高耦合性。
简而言之,耦合不仅仅是模块,而是模块之间的连接以及两个模块之间的相互作用或相互依存程度。如果两个模块包含大量数据,那么它们是高度相互依赖的。
如果组件之间的连接是强的,我们谈论的是强耦合模块;当连接较弱时,我们谈论松散耦合的模块。
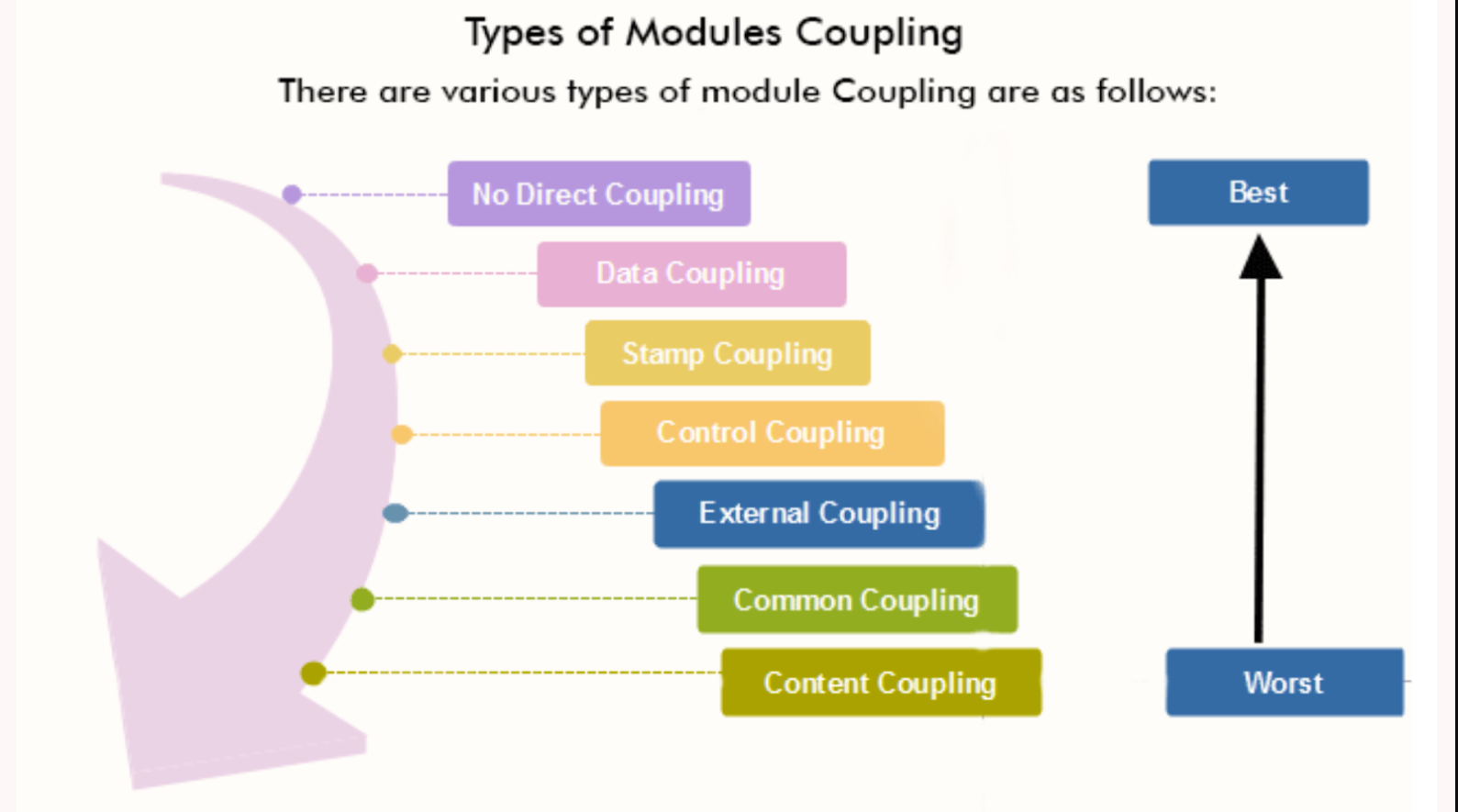
软件工程中的耦合有哪些不同类型?

1.数据耦合
当模块通过参数或自变量共享数据时,就会发生数据耦合。
每个模块都维护自己的数据,并不完全访问或修改其他模块的数据。
这种类型的耦合促进了封装和模块的相互依赖性。
2.印记耦合
印记耦合是一种较弱的耦合形式,其中模块共享一个复合数据结构,但并非每个模块都使用所有元素。
由于数据和元素是预先组织好的并放置好的,因此在两个耦合模块之间不会共享或传递垃圾或未使用的数据,这提高了模块的效率。
3.控制耦合
当一个模块控制另一个模块的行为时,就会发生控制耦合。
这种类型的耦合意味着一个模块或另一个模块具有内部工作和决策的知识,这使得代码更难维护。
4.外部耦合
外部耦合衡量系统依赖外部实体来实现其功能或与外部环境交互的程度。
- 低外部耦合-外部实体的变化对系统的内部实现几乎没有影响。
- 中间外部耦合-外部实体的更改需要在系统内进行一些修改,以适应新的接口。
- 高度外部耦合-外部实体的变化对系统的内部实施产生重大影响,需要进行大量修改。
5.公共耦合
当系统中的两个或多个模块共享全局数据时,会发生公共耦合。
模块可以访问和操作相同的全局变量和数据结构。
6.内容耦合
当一个模块直接访问或修改另一个模块的内容时,就会发生内容耦合。
这种类型的耦合是强烈的,也是不可取的,因为它将模块紧密耦合,使它们高度独立于彼此的实现。
内聚和耦合之间的关系是什么?
软件工程中内聚和耦合之间的关系可以由以下因素决定:
- 反向关系-当内聚力高时,耦合度往往较低。高内聚性意味着模块中的元素密切相关,共同努力实现既定目的。
- 设计目标-高内聚性和低耦合性有助于提高软件系统的可维护性、可重用性和灵活性。
- 对软件质量的影响-高内聚性有助于代码库更好的理解性、可读性和可维护性。低耦合降低了模块之间的相互依赖性。
- 权衡-开发人员需要根据系统的具体需求和约束条件来达成平衡。
什么是内聚和耦合度量?
这些是用于评估软件工程中的耦合和内聚水平的定量度量。以下是一些常见指标:
内聚性度量
1.缺乏凝聚方法(LCOM)
通过模块中不相交的方法集的数量计算。
LCOM值越高表示内聚力越低。
2.LCOM2
通过不相交的方法集的数量计算,但与LCOM相比,它提供了更精细的内聚度量。
3.紧密类粘聚(TCC)
表示访问相同属性的方法对的比例。
TCC值越高表示凝聚力越强。
耦合度量
1.对象之间的耦合(CBO)
CBO测量类所耦合的其他类或对象的数量。
较高的CBO值表明增加了耦合性,降低了可重用性。
2.类的响应(RFC)
RFC测量类中可以响应该类的对象接收到的消息而执行的方法的数量。
较高的RFC值表示较高的复杂性。
3.继承树深度(DIT)
DIT度量类的继承层次结构中的级别数。
DIT值越高,表示继承树越深,耦合性越强。
- 80 次浏览
【软件设计原则】CUPID——快乐的编码
最初是轻描淡写的偶像破坏,戳着 SOLID 的熊市,现在已经发展成更具体和有形的东西。如果我认为这些天 SOLID 原则没有用,那么我会用什么来代替它们呢?任何一套原则都适用于所有软件吗?我们所说的原则是什么意思?
我相信软件的某些特性或特征使它成为一种乐趣。您的代码越具有这些品质,使用起来就越愉快;但一切都是权衡,因此您应该始终考虑您的上下文。
可能有许多这些特性,重叠和相互关联,并且有很多方法可以描述它们。我选择了五个支持我在代码中关心的大部分内容。收益递减;五个就足以成为一个方便的首字母缩略词,而且足以记住。
我将在以后的文章中对每个特性进行扩展,以便不再获得这个特性,所以请原谅我没有更全面。
五个 CUPID 特性是:
- 可组合(Composable):与他人相处融洽
- Unix哲学(Unix philosophy):做好一件事
- 可预测(Predictable):做你所期望的
- 惯用语(Idiomatic):感觉自然
- 基于领域(Domain-based):解决方案领域在语言和结构上对问题领域进行建模
序言:很久以前……¶
您是否曾经破解过一个不熟悉的代码库并且只知道如何绕过?结构、命名、流程很明显,有点熟悉。笑容出现在你的脸上。 “我有这个!”您认为。
在三十年的职业生涯中,我有幸经历过几次这样的经历,每一次都让我充满喜悦。第一次是在 1990 年代初——我记得很清楚——当时我打开了一个巨大的 C 代码库,它为数字印刷进行复杂的图像处理。别人的代码™中有一个错误,我要追踪并修复它。我记得作为一个新手程序员的感觉:既害怕又害怕背叛自己,因为我知道自己是个业余爱好者。
我的编辑器——带有 ctags 的 vi——允许我从调用站点导航到函数定义,几分钟之内,我就深入到一个调用嵌套中,在一个包含数百个源文件和头文件的代码库中,我确信我知道什么我在看。我很快找到了罪魁祸首,这是一个简单的逻辑错误,进行了更改,构建了代码并对其进行了测试。这一切都没有自动化测试,只是使用 Makefiles。 TDD 在我的未来将近十年,而 C 在任何情况下都没有那种工具。
我对几个示例图像进行了转换,结果看起来还不错。我尽我所能确信我已经 a) 发现并修复了错误,并且 b) 没有同时引入任何令人讨厌的惊喜。
快乐软件¶
一些代码是一种愉快的工作。你知道如何找到你需要做的事情。你知道如何做出你需要的改变。该代码易于浏览,易于理解,易于推理。您确信您的更改将产生您想要的效果,而不会产生任何过度的副作用。代码引导你,邀请你环顾四周。在你之前来的程序员在乎后来的人,也许是因为他们意识到后来的程序员可能就是他们!
Martin Fowler 在他的开创性著作《重构》中说:
“任何傻瓜都可以编写计算机可以理解的代码。优秀的程序员编写人类可以理解的代码。”
——重构,Martin Fowler 和 Kent Beck,1996
我在 2000 年代初读到了这篇文章,他的话让我的编程世界彻底颠覆了。如果好的编程是为了让其他人可以理解代码呢?如果其中一个人类是未来的我怎么办?这听起来像是一件令人向往的事情。
但是,虽然“可以理解”可能是一个崇高的愿望,但它并不是那么高的标准!大约在 Martin 撰写有关重构的文章的同时,计算先驱 Richard P. Gabriel 描述了代码可居住的想法:
“宜居性是源代码的特性,它使 [人们] 能够理解其结构和意图,并舒适而自信地对其进行更改。
“宜居性使一个地方像家一样宜居。”
— 可居住性和零碎增长1,软件模式第 7-16 页,Richard P. Gabriel
这感觉更像是要争取的东西。改变其他人的代码感到自在和自信会有多好?如果我们可以让代码变得宜居,那么快乐呢?代码库有可能让你充满喜悦吗?
如果您将工作日花在编程上,那么导航和操作代码库将定义您的用户体验。你可以体验到惊喜、沮丧、恐惧、期待、无助、希望、喜悦,这一切都是因为早期程序员在代码库中做出的选择。
如果我们假设代码库可能是快乐的,那么每个代码库是否都有自己特殊的雪花,它对你的心灵的影响是独一无二的?或者我们能否阐明是什么让它变得快乐,并提供一条途径来增加我们接触的代码的快乐?
特性高于原则¶
当我开始对 SOLID 的五项原则做出回应时,我设想用我认为更有用或更相关的东西来替换每一项。我很快意识到原则的想法本身是有问题的。原则就像规则:你要么顺从,要么不顺从。这就产生了规则追随者和规则执行者的“有界集合”,而不是具有共同价值观的人的“中心集合”。 2
相反,我开始考虑特性:代码的品质或特征,而不是要遵循的规则。特性定义要移动的目标或中心。您的代码只是离中心更近或更远,并且始终有明确的行进方向。您可以使用特性作为镜头或过滤器来评估您的代码,并且您可以决定接下来要解决哪些问题。由于 CUPID特性都是相互关联的,因此您为改进一个特性所做的任何更改都可能对其他一些特性产生积极影响。
特性的特性¶
那么我们如何选择特性呢?是什么让特性或多或少有用?我决定了三个我希望 CUPID 特性具有的“特性的特性”。它们应该是实用的、人性化的和分层的。
为了实用,特性需要:
- 易于表达:因此您可以用几句话描述它们中的每一个,并提供具体的例子和反例。
- 易于评估:因此您可以将它们用作审查和讨论代码的镜头,并且您可以轻松确定代码展示了每个特性的程度。
- 易于采用:因此您可以从小规模开始并沿着任何 CUPID 维度逐步发展代码。没有“全押”,也没有“失败”,就像从来没有“完成”一样。代码总是可以改进的。
作为人类,特性需要从人的角度来阅读,而不是代码。 CUPID 是关于使用代码的感觉,而不是对代码本身的抽象描述。例如,虽然“做好一件事”的 Unix 哲学听起来像单一职责原则,但前者是关于你如何使用代码,而后者是关于代码本身的内部结构。 3
要分层,特性应该为初学者提供指导——这是易于表达的结果——并为那些发现自己想要更深入地探索软件本质的更有经验的人提供细微差别。每个 CUPID 特性都是“显而易见的”,只是名称和简要描述,但每个特性都包含许多层、维度和方法。我们也许可以描述每个特性的“中心”,但是有很多路径可以到达那里!
可组合¶
易于使用的软件会被使用、使用并再次使用。有一些特征使代码或多或少可组合,但这些对于做出任何保证既不是必要的也不是充分的。在每种情况下,我们都可以找到双方的反例,因此您应该将这些视为有用的启发式方法。更多不一定更好;这都是取舍。
小表面积¶
具有狭窄、固执己见的 API 的代码让您学习的东西更少,出错的可能性也更少,与您正在使用的其他代码发生冲突或不一致的可能性也更小。这有一个递减的回报;如果您的 API 太窄,您会发现自己将它们组合在一起使用,并且了解常见用例的“正确组合”会成为可能成为进入障碍的隐性知识。获得正确的 API 粒度比看起来更难。碎片化和臃肿之间有一个“恰到好处”的凝聚力。
意图揭示¶
意图揭示代码很容易发现和评估。我可以很容易地找到您的组件,并尽快决定它是否是我需要的东西。我喜欢的一个模型——来自像古老的 XStream 这样的开源项目——有一个 2 分钟的教程、一个 10 分钟的教程和一个深入研究。这让我可以增量投资,并在我发现这不适合我时立即退出。
我不止一次开始编写一个类,给它一个意图揭示的名称,只是为了让 IDE 弹出一个具有相同名称的建议导入。通常结果是其他人也有同样的想法,我偶然发现了他们的代码,因为我们选择了相似的名字。这不仅仅是巧合;我们精通同一个领域,这使得我们更有可能选择相似的名字。当您拥有基于域的代码时,这种情况更有可能发生。
最小依赖¶
具有最小依赖性的代码让您不必担心,并降低版本或库不兼容的可能性。我用 Java 编写了我的第一个开源项目 XJB,并使用了几乎无处不在的 log4j 日志框架。一位同事指出,这创建了一个依赖关系,不仅依赖于作为库的 log4j,而且依赖于特定的版本。我什至没有想到。为什么有人要担心像日志库这样无害的东西?因此,我们删除了依赖项,甚至提取了一个完整的其他项目,该项目使用 Java 动态代理做有趣的事情,它本身具有最小的依赖项。
Unix 哲学 ¶
Unix和我差不多大;我们都始于 1969 年,而 Unix 已成为地球上最流行的操作系统。在 1990 年代,每个严肃的计算机硬件制造商都有自己的 Unix,直到关键的开源变体 Linux 和 FreeBSD 变得无处不在。如今,它以 Linux 的形式运行几乎所有的业务服务器,包括云服务器和本地服务器;它在嵌入式系统和网络设备中运行;它支持 macOS 和 Android 操作系统;它甚至作为 Microsoft Windows 的可选子系统提供!
一个简单、一致的模型¶
那么,一个从电信研究实验室开始的小众操作系统是如何被一个大学生作为爱好项目复制的,最终成为世界上最大的操作系统呢?毫无疑问,在一个操作系统供应商因其技术而闻名的时代,它的成功有商业和法律原因,但其持久的技术吸引力在于其简单而一致的设计理念。
Unix 哲学说要编写能够很好地协同工作的 [组件],在上面的可组合性特性中进行了描述,并且只做一件事并且做好。4 例如,ls 命令列出了有关文件和目录的详细信息,但它不知道关于文件或目录的任何事情!有一个名为 stat 的系统命令提供信息; ls 只是将信息显示为文本的工具。
同样,cat 命令打印(连接)一个或多个文件的内容,grep 选择与给定模式匹配的文本,sed 替换文本模式,等等。 Unix 命令行具有强大的“管道”概念,它将一个命令的输出作为输入附加到下一个命令,创建一个选择、转换、过滤、排序等管道。您可以编写复杂的文本和数据处理程序,这些程序基于组合一些精心设计的命令,每个命令都做一件事,而且做得很好。
单一目的与单一职责 ¶
乍一看,这看起来像是单一职责原则 (SRP),对于 SRP 的某些解释,存在一些重叠。但“做好一件事”是一种由外而内的观点;它具有特定、明确和全面的目的。 SRP 是一个由内而外的观点:它是关于代码的组织。
SRP,用创造这个词的 Robert C. Martin 的话来说是,[代码]“应该有一个,而且只有一个,改变的理由。” Wikipedia 文章中的示例是一个生成报告的模块,您应该在其中将报告的内容和格式视为单独的关注点,它们应该存在于单独的类中,甚至是单独的模块中。正如我在其他地方所说,根据我的经验,这会产生人为的接缝,最常见的情况是数据的内容和格式一起改变;例如,一个新字段或对某些数据源的更改会影响其内容和您希望显示它的方式。
另一个常见场景是“UI 组件”,其中 SRP 要求您将组件的呈现和业务逻辑分开。作为开发人员,让这些人生活在不同的地方会导致将相同字段链接在一起的行政工作。更大的风险是,这可能是一种过早的优化,会阻止随着代码库的增长而出现的更自然的关注点分离,以及随着“做好一件事”并且更适合问题空间的域模型的组件的出现。随着任何代码库的增长,将其分离为合理的子组件的时候到了,但是可组合性和基于域的结构的特性将更好地指示何时以及如何进行这些结构更改。
可预测的 ¶
代码应该做它看起来做的事情,一致且可靠,没有令人不快的意外。这不仅应该是可能的,而且应该很容易确认。从这个意义上说,可预测性是可测试性的概括。
可预测的代码应该按预期运行,并且应该是确定性和可观察的。
表现如预期¶
Kent Beck 的四项简单设计规则中的第一条是代码“通过了所有测试”。即使没有测试,这也应该是正确的!可预测代码的预期行为应该从其结构和命名中显而易见。如果没有自动化测试来实现这一点,那么编写一些应该很容易。 Michael Feathers 将这些特性称为测试。用他的话说:
“当一个系统投入生产时,在某种程度上,它变成了它自己的规范。”——迈克尔·费瑟斯
这不是必需的,我发现有些人认为测试驱动开发是一种信仰,而不是一种工具。我曾经开发过一个复杂的算法交易应用程序,它的“测试覆盖率”约为 7%。这些测试分布不均!大部分代码根本没有自动化测试,有些代码有大量复杂的测试,检查细微的错误和边缘情况。我有信心对大部分代码库进行更改,因为每个组件都做一件事,而且它的行为是直接且可预测的,因此更改通常是显而易见的。
确定性¶
软件每次都应该做同样的事情。即使设计为非确定性的代码(例如随机数生成器或动态计算)也将具有您可以定义的操作或功能界限。您应该能够预测内存、网络、存储或处理边界、时间边界以及对其他依赖项的期望。
决定论是一个广泛的话题。出于可预测性的目的,确定性代码应该是健壮的、可靠的和有弹性的。
- Robustness :稳健性是我们涵盖的情况的广度或完整性。限制和边缘情况应该是显而易见的。
- Reliability :在我们涵盖的情况下,可靠性按预期运行。我们每次都应该得到相同的结果。
- Resilience :复原力是我们处理未涵盖的情况的能力;输入或操作环境中的意外扰动。
可观察的¶
代码在控制理论的意义上应该是可观察的:我们可以从它的输出推断它的内部状态。这只有在我们设计时才有可能。一旦几个组件交互,尤其是异步交互,就会出现紧急行为和非线性后果。
从一开始就检测代码意味着我们可以获得有价值的数据来了解其运行时特性。我描述了一个四阶段模型——有两个奖励阶段!——像这样:
- Instrumentation :Instrumentation 是您的软件说明它在做什么。
- Telemetry :遥测使这些信息可用,无论是通过拉(请求)还是推送(发送消息); “远距离测量”。
- Monitoring :监控正在接收仪器并使其可见。
- Alerting :警报是对监控的数据或数据中的模式做出反应。
奖金:
- Predicting :预测是使用这些数据在事件发生之前对其进行预测。
- Adapting :适应是动态地改变系统,以抢占或从预测的扰动中恢复。
大多数软件甚至都没有通过第 1 步。有一些工具可以拦截或改变正在运行的系统以增加洞察力,但这些工具永远不如为应用程序设计的故意仪表。
惯用语¶
每个人都有自己的编码风格。无论是空格还是制表符、缩进大小、变量命名约定、大括号或圆括号的位置、源文件中的代码布局,还是无数其他可能性。在此之上,我们可以对库、工具链、生存路径、甚至版本控制注释样式或提交粒度的选择进行分层。 (你确实使用版本控制,不是吗?)
这会给使用不熟悉的代码增加显着的额外认知负担。除了理解问题域和解决方案空间之外,您还必须解释其他人的意思,以及他们的决定是经过深思熟虑的和上下文相关的,还是任意的和习惯性的。
最大的编程特质是同理心。同情你的用户;对支持人员的同理心;对未来开发者的同理心;任何人都可能成为未来的你。编写“人类可以理解的代码”意味着为其他人编写代码。这就是惯用代码的含义。
在这种情况下,您的目标受众是:
- 熟悉该语言、它的库、它的工具链和它的生态系统
- 了解软件开发的经验丰富的程序员
- 努力完成工作!
语言习语¶
代码应该符合语言的习惯用法。有些语言对代码的外观有强烈的看法,这使得评估代码的惯用程度变得容易。其他人不那么固执己见,这让你有责任“选择一种风格”然后坚持下去。 Go 和 Python 是固执己见的语言的两个例子。
Python 程序员使用术语“pythonic”来描述惯用代码。如果你从 Python REPL 导入它,或者从 shell 运行 python -m this,就会出现一个美妙的复活节彩蛋。它打印了一个名为“Python 之禅”的编程格言列表,其中包括这一行,抓住了惯用代码的精神:“应该有一种——最好只有一种——明显的方式来做到这一点。”
Go 语言附带了一个名为 gofmt 的代码格式化程序,它使所有源代码看起来都一样。这一下子消除了关于缩进、大括号放置或其他语法怪癖的任何分歧。这意味着您在库文档或教程中看到的任何代码示例看起来都是一致的。他们甚至有一个名为 Effective Go 的文档,展示了语言定义之外的惯用 Go。
光谱的另一端是 Scala、Ruby5、JavaScript 和古老的 Perl 等语言。这些语言是故意的多范式; Perl 创造了首字母缩略词 TIMTOWTDI——“有不止一种方法可以做到”——发音为“Tim Toady”。您可以在其中的大多数中编写函数式、过程式或面向对象的代码,这会从您所知道的任何一种语言中创建一个浅薄的学习曲线。
对于处理一系列值这样简单的事情,这些语言中的大多数都允许您:
- 使用迭代器
- 使用索引 for 循环
- 使用条件 while 循环
- 使用带有收集器的函数管道(“map-reduce”)
- 写一个尾递归函数
这意味着在任何不平凡的代码大小中,您都可能会找到其中每一个的示例,通常是相互结合的。同样,这一切都会增加认知负担,影响您思考手头问题的能力,增加不确定性并减少快乐。
代码习语出现在所有粒度级别:命名函数、类型、参数、模块;代码布局;模块结构;工具的选择;依赖项的选择;你如何管理依赖关系;等等。
无论您的技术堆栈处于自以为是的范围内,如果您花时间学习该语言的习语、它的生态系统、它的社区和它的首选风格,您编写的代码将会更加富有同情心和快乐。
您对一项技术的学习曲线可能比您在其中编写的任何代码都更短,因此抵制编写现在对您来说很好读的代码的冲动很重要,因为那个人不会存在很长时间!确信您正在编写惯用代码的唯一方法是花时间学习惯用语。
地方习语 ¶
当一种语言在惯用风格或几种替代方案方面没有达成共识时,由您和您的团队来决定“好的”是什么样的,并引入约束和指导方针以鼓励一致性。这些约束可以很简单,例如 IDE 中的共享代码格式化规则、检查和批评代码的“构建 cop”工具,以及标准工具链上的协议。
架构决策记录 6 或 ADR 是记录您对风格和习语的选择的好方法。与任何其他架构讨论相比,这些都是“重要的技术决策”。
基于域 ¶
我们编写软件来满足需要。这可能是具体的和情境化的,也可能是笼统的和影响深远的。不管它的目的是什么,代码都应该用问题域的语言来表达它正在做什么,以最小化你写的东西和它所做的事情之间的认知距离。这不仅仅是“使用正确的词”。
基于领域的语言 ¶
编程语言及其库充满了计算机科学结构,如哈希映射、链接列表、树集、数据库连接等。它们具有包括整数、字符、布尔值的基本类型。您可以将某人的姓氏声明为字符串 [30],这很可能是它的存储方式,但定义姓氏类型将更能揭示意图。它甚至可能具有与姓氏相关的操作、特性或约束。银行软件中的许多细微错误是由于将金额表示为浮点值;有经验的金融软件程序员会定义一个 Money 类型,其中包含 Currency 和 Amount,它本身就是一个复合类型。
正确命名类型和操作不仅仅是为了捕捉或防止错误,而是为了让代码中的解决方案空间更容易表达和导航。这是我对“每个程序员都应该知道的 97 件事”的贡献,即“领域语言中的代码”。
领域驱动代码成功的一个标准是,不经意的观察者无法判断人们是在讨论代码还是在讨论领域。我曾经在一个电子交易系统中遇到过这种情况,一位金融分析师正在与两名程序员讨论复杂的交易定价逻辑。我以为他们在讨论定价规则,但他们指着一屏代码,分析师正在通过定价算法与程序员交谈,这是代码如何逐行读取的!问题域和解决方案代码之间唯一的认知距离是一些语法标点符号!
基于域的结构¶
使用基于域的语言很重要,但如何构建代码也同样重要。许多框架都提供了一个“骨架项目”,其目录布局和存根文件旨在帮助您快速入门。这会在您的代码上强加一个与您正在解决的问题无关的先验结构。
相反,代码的布局——目录名称、子文件夹和同级文件夹的关系、相关文件的分组和命名——应该尽可能地反映问题域。
应用程序框架 Ruby on Rails 在 2000 年代初期通过将其构建到其工具中而普及了这种方法,Rails 的广泛采用意味着许多后来的框架都复制了这个想法。 CUPID 与语言和框架无关,但 Rails 提供了一个有用的案例研究来理解基于域的结构和基于框架的结构之间的区别。
下面是生成的 Rails 应用程序的部分目录布局,重点关注开发人员将花费大部分时间的目录(应用程序)。在撰写本文时,完整的框架运行到大约 50 个目录,其中包含 60 个文件7。
app
├── assets
│ ├── config
│ ├── images
│ └── stylesheets
├── channels
│ └── application_cable
├── controllers
│ └── concerns
├── helpers
├── javascript
│ └── controllers
├── jobs
├── mailers
├── models
│ └── concerns
└── views
└── layouts
想象一下,这将是一个医院管理应用程序,其中有一个病人记录部分。这种布局表明我们至少需要:
- 一个模型,它映射到某处的数据库
- 一个视图,在屏幕上呈现患者记录
- 一个控制器,在视图和模型之间进行调解
然后是帮助器、资产和其他几个框架概念的范围,例如模型关注点或控制器关注点、邮件程序、作业、通道,以及可能与 Ruby 控制器一起使用的 JavaScript 控制器。这些人工制品中的每一个都存在于一个单独的目录中,即使它们在语义上是紧密集成的。
对患者记录管理的任何重大更改都可能涉及分散在代码库中的代码。单一职责的 SOLID 原则说视图代码应该与控制器代码分开,并且像 Rails 这样的框架将其解释为意味着将它们放在完全不同的位置。这增加了认知负荷,降低了凝聚力,并增加了进行产品更改的努力。正如我之前所讨论的,这种意识形态约束会使工作更加困难,代码库的乐趣也会降低。
我们仍然需要模型、视图和控制器等人工制品,无论我们以何种方式布置代码,但按类型对它们进行分组不应形成主要结构。相反,代码库的顶层应该显示医院管理的主要用例;也许是患者历史、约会、人员配备和合规性。
对代码结构采用基于域的方法可以很容易地理解代码的用途,并且可以轻松导航到任何比“使该按钮变成浅蓝色”更复杂的地方。
基于域的边界¶
当我们按照我们想要的方式构建代码并按照我们想要的方式命名时,模块边界就变成了域边界,部署就变得简单了。将组件部署为单个工件所需的一切都在一起,因此我们可以将域边界与部署边界对齐,并部署有凝聚力的业务组件和服务。无论您将您的产品或服务打包为单个单体、许多小型微服务,还是介于两者之间的任何地方,这种一致性都降低了您的生存路径的复杂性,并降低了您忘记某些东西或包含来自不同环境的人工制品或不同的子系统。
这并不限制我们使用单一的、扁平的、顶级的代码结构。域可以包含子域;组件可以包含子组件;部署可以在对您的变更和风险状况有意义的任何粒度级别进行。将代码边界与域边界对齐可以使所有这些选项更易于推理和管理。
结论性想法¶
我相信拥有更多这些特性的代码——可组合性、Unix 哲学、可预测性,或者是惯用的或基于域的——比不具备这些特性的代码更令人愉悦。虽然我独立评估每个特征,但我发现它们是相辅相成的。
既可组合又全面的代码——做好一件事——就像一个可靠的朋友。即使您以前从未见过惯用代码,也感觉很熟悉。可预测的代码为您提供了空闲周期来专注于其他地方的惊喜。基于领域的代码最小化了从需求到解决方案的认知距离。将代码移向这些特性中的任何一个的“中心”会比你发现的更好。
因为 CUPID 是一个反义词,所以每个字母我都有几个候选者。我之所以选择这五个,是因为它们以某种方式感到“基础”;我们可以从中得出所有其他候选特性。未来的文章将探讨一些没有入选的候选名单特性,并看看它们是如何成为编写 CUPID 软件的自然结果。
我很想听听人们与 CUPID 的冒险经历。我已经听说有团队使用这些特性来评估他们的代码,并制定清理遗留代码库的策略,我迫不及待地想听到经验报告和案例研究。与此同时,我想更深入地了解 CUPID,依次探索每个特性,看看还有什么隐藏在显而易见的地方。
- 我建议任何参与软件开发的人,而不仅仅是程序员,阅读这篇短文。这是一篇深刻而优美的文字。 ↩︎
- 在 1970 年代,人类学家和基督教传教士(传教士的观察者)保罗·G·希伯特(Paul G. Hiebert)使用有界和中心集的数学概念来对比“有界”社区,这些社区通过谁在谁在外面的规则来定义自己,与“中心”社区一起,他们通过一组核心价值观来定义自己,人们更接近或远离这些核心价值观,但从不“外部”。 ↩︎
- 单一职责的定义是代码应该有“一个且只有一个改变的理由”,例如,你应该将 UI 代码与业务逻辑分开。这种约束不仅很容易被驳斥——因为出于安全性、合规性、上游或下游依赖性、操作特性等原因,即使是一行代码也可能需要更改,而且我认为它是一个任意约束往往是过早的隔离,带来负面后果。 ↩︎
- 除此之外,Unix 操作系统的设计还有一个优雅的简洁性:一切都是文件;一切要么是文字,要么不是文字;我们通过一系列转换处理文本来构建整个程序。 ↩︎
- Ruby 在这里可能是一个异常值,因为肯定存在“Ruby 美学”,并且很多人都写过“惯用的 Ruby”,但这仍然是个人分享他们喜欢的编程风格,而不是社区固有的任何东西。 ↩︎
- 架构决策记录由 Michael Nygard 于 2011 年首次提出,此后一直在发展。 ↩︎
- 关于框架应该为“原始”项目的开发人员施加多少脚手架和生成的样板,还有一个完整的其他讨论,这超出了本文的范围。 ↩︎
- 54 次浏览
【韧性设计】韧性设计模式:重试、回退、超时、断路器
什么是韧性?
软件本身并不是目的:它支持您的业务流程并使客户满意。如果软件没有在生产中运行,它就无法产生价值。然而,生产性软件也必须是正确的、可靠的和可用的。
当谈到软件设计中的弹性时,主要目标是构建健壮的组件,这些组件既可以容忍其范围内的故障,也可以容忍它们所依赖的其他组件的故障。虽然自动故障转移或冗余等技术可以使组件具有容错性,但如今几乎每个系统都是分布式的。即使是一个简单的 Web 应用程序也可以包含 Web 服务器、数据库、防火墙、代理、负载平衡器和缓存服务器。此外,网络基础设施本身由许多组件组成,因此总是会在某处发生故障。
除了完全失败的情况外,服务也可能需要更长的时间来响应。实际上,尽管他们的响应格式是正确的,但他们甚至可能以错误的方式回答语义。同样,系统拥有的组件越多,发生故障的可能性就越大。
可用性通常被认为是一个重要的质量属性。它表示一个组件实际可用的时间量,与该组件应该可用的时间量相比。可以用以下公式表示:

传统方法旨在增加正常运行时间,而现代方法旨在减少恢复时间,从而减少停机时间。 这很有用,因为它允许我们处理故障,而不是不惜一切代价阻止它们,并且在它们发生时长时间不可用。 Uwe Friedrichsen 将弹性设计模式分为四类:松散耦合、隔离、延迟控制和监督(Loose coupling, isolation, latency control, and supervision)。
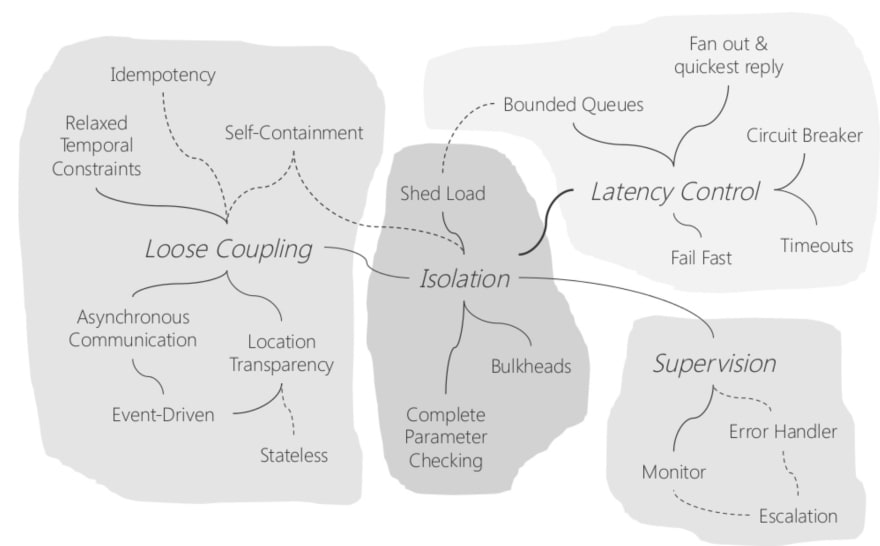
在这篇博文中,我们想看看延迟控制类别中的四种模式:重试、回退、超时和断路器。在理论介绍之后,我们将看到如何使用 Eclipse Vert.x 在实践中应用这些模式。我们将通过讨论替代实现并总结调查结果来结束这篇文章。
模式
示例场景
为了说明模式的功能,我们将使用一个非常简单的示例用例。想象一下作为购物平台一部分的支付服务。当客户想要付款时,支付服务应确保没有欺诈意图。为此,它要求提供欺诈检查服务。
在这种情况下,我们的服务提供基于 HTTP 的接口。为了检查交易,支付服务向欺诈检查服务发送 HTTP 请求。如果一切正常,将会有一个 200 响应,其中的布尔值指示交易是否是欺诈性的。但是,如果欺诈检查服务没有回答怎么办?如果它返回内部服务器错误(500)怎么办?
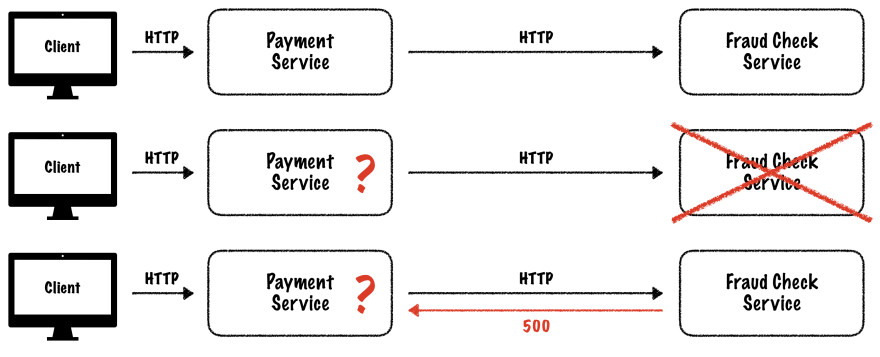
现在让我们看一下解决可能的通信问题的四种具体模式。 虽然这是一个具体示例,但您可以想象任何其他涉及通过不可靠信道与不可靠服务进行通信的星座。
重试
每当我们假设可以通过再次发送请求来修复意外响应(或没有响应)时,使用重试模式会有所帮助。 这是一种非常简单的模式,失败的请求会在失败的情况下重试可配置的次数,然后才会将操作标记为失败。
下面的动画说明了支付服务试图发出欺诈支票。 由于欺诈检查服务中的内部服务器错误,第一个请求失败。 支付服务重试请求并收到交易不是欺诈的答案。

重试在以下情况下很有用
- 丢包等临时网络问题
- 目标服务的内部错误,例如由数据库中断引起
- 由于对目标服务的大量请求而没有响应或响应缓慢
但是请记住,如果问题是由目标服务过载引起的,重试可能会使这些问题变得更糟。为避免将弹性模式转变为拒绝服务攻击,可以将重试与其他技术结合使用,例如指数退避或断路器(见下文)。
倒退(Fallback)
回退模式使您的服务能够在对另一个服务的请求失败的情况下继续执行。我们不会因为缺少响应而中止计算,而是填写一个备用值。
下面的动画再次描绘了支付服务向欺诈检查服务发出请求。同样,欺诈检查服务返回内部服务器错误。然而,这一次,我们有一个备用方案,它假设交易不是欺诈性的。

备用值并不总是可行的,但如果小心使用,可以大大提高您的整体弹性。在上面的示例中,如果欺诈检查服务不可用,则回退到将交易视为非欺诈可能是危险的。它甚至为试图首先向服务发送垃圾邮件然后进行欺诈交易的欺诈交易打开了攻击面。
另一方面,如果后备是假设每笔交易都是欺诈性的,则不会进行任何付款,并且后备基本上是无用的。一个好的折衷方案可能是回退到一个简单的业务规则,例如简单地让相当少量的交易通过,以在风险和不失去客户之间取得良好的平衡。
Timeout(超时)
超时模式非常简单,许多 HTTP 客户端都配置了默认超时。目标是避免响应的无限等待时间,从而在超时内未收到响应的情况下将每个请求视为失败。
下面的动画显示了支付服务等待欺诈检查服务的响应并在超时后中止操作。

几乎每个应用程序都使用超时,以避免请求永远卡住。然而,处理超时并非易事。想象一下在网上商店下订单超时。您无法确定订单是否成功下达,但如果订单创建仍在进行中或请求从未处理,则响应超时。如果将超时与重试结合起来,您可能会得到重复的订单。如果您将订单标记为失败,客户可能会认为订单没有成功,但也许确实成功了,他们会被收费。
此外,您希望您的超时时间足够高以允许较慢的响应到达,但又足够低以停止等待永远不会到达的响应。
断路器
在电子产品中,断路器是一种开关,可保护您的组件免受过载损坏。在软件中,断路器可以保护您的服务不被垃圾邮件发送,同时由于高负载已经部分不可用。
Martin Fowler 描述了断路器模式。它可以实现为一个有状态的软件组件,在三种状态之间切换:关闭(请求可以自由流动)、打开(请求被拒绝而不提交给远程资源)和半打开(允许一个探测请求决定是否再次关闭电路)。下面的动画说明了一个正在运行的断路器。
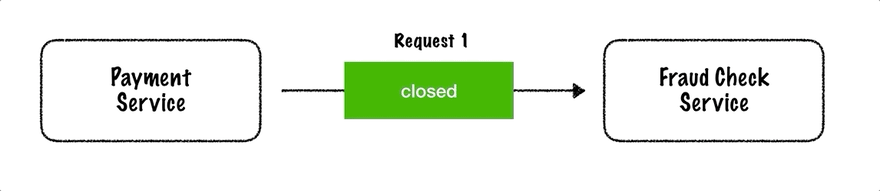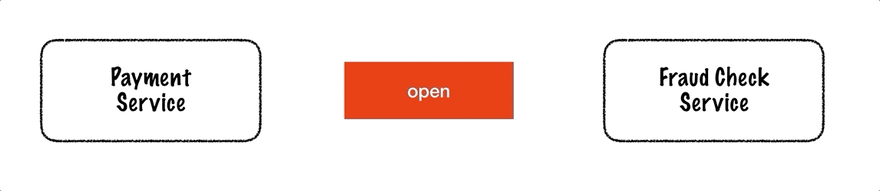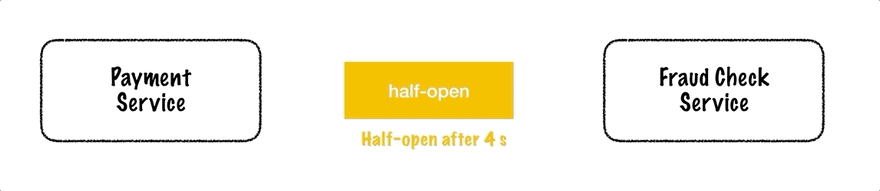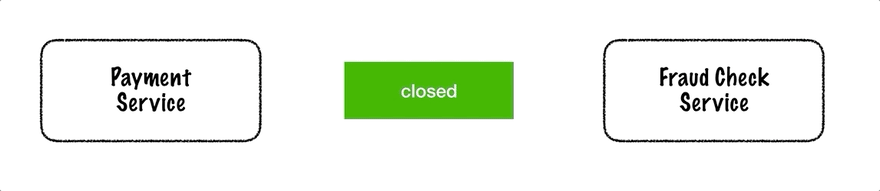
从支付服务到欺诈检查服务的请求通过断路器传递。在两次内部服务器错误之后,电路打开并且后续请求被阻止。等待一段时间后,电路进入半开状态。在这种状态下,它将允许一个请求在失败的情况下通过并变回打开状态,或者在成功的情况下关闭。下一个请求成功,因此电路再次关闭。
断路器是一种有用的工具,尤其是在与重试、超时和回退结合使用时。回退不仅可以在发生故障的情况下使用,也可以在电路开路的情况下使用。在下一节中,我们将看一个用 Kotlin 编写的 Vert.x 代码示例。
Vert.x 中的实现
在上一节中,我们从理论的角度研究了不同的弹性模式。现在让我们看看如何实现它们。该示例的源代码可在 GitHub 上找到。我们将在这个展示中使用 Vert.x 和 Kotlin。下一节将讨论其他替代方案。
Vert.x 提供了 CircuitBreaker,这是一个强大的装饰器类,它支持重试、回退、超时和断路器配置的任意组合。您可以使用 CircuitBreakerOptions 类配置断路器,如下所示。
val vertx = Vertx.vertx() val options = circuitBreakerOptionsOf( fallbackOnFailure = false, maxFailures = 1, maxRetries = 2, resetTimeout = 5000, timeout = 2000 ) val circuitBreaker = CircuitBreaker.create("my-circuit-breaker", vertx, options)
在这个例子中,我们正在创建一个断路器,它在将其视为失败之前重试操作两次。在一次故障后,我们打开电路,该电路将在 5000 毫秒后再次半开。操作在 2000 毫秒后超时。如果指定了回退,则仅在开路的情况下才会调用它。也可以将断路器配置为在发生故障时调用回退,即使电路已关闭。
为了执行命令,我们需要提供一段异步代码来执行 Handler<Future<T>> 类型以及处理结果的 Handler<AsyncResult<T>> 类型的处理程序。返回 OK 并在之后打印它的最小示例如下所示:
circuitBreaker.executeCommand( Handler<Future<String>> { it.complete("OK") }, Handler { println(it) } )
在 Kotlin 中使用 Vert.x 时,您还可以将挂起函数作为参数传递,而不是使用处理程序。更多细节请参考 CoroutineHandlerFactory 类及其用法。除了这些基本功能之外,Vert.x 断路器模块还提供以下高级功能:
- 事件总线通知。断路器可以在每次状态更改时将事件发布到事件总线。如果您想以某种方式对这些事件做出反应,这很有用。
- 指标。断路器可以发布要由 Hystrix 仪表板使用的指标,以可视化断路器的状态。
- 状态更改回调。您可以配置在电路打开或关闭时调用的自定义处理程序。
替代实施方法
并非每个框架都支持开箱即用的弹性设计模式。 Vert.x 也不支持所有可能的模式。有一些指定项目直接解决弹性主题,例如 Hystrix、resilience4j、failsafe和 Istio 的弹性特性。
Hystrix 已在许多应用程序中使用,但不再处于积极开发中。 Hystrix、resilience4j 以及故障安全都是从应用程序源代码中直接调用的。例如,您可以通过实现接口或使用注释来集成它。
另一方面,Istio 是一个服务网格,因此是基础架构的一部分,而不是应用程序代码。它用于编排分布式服务系统并实现边车的概念。服务通信通过那个 sidecar 发生,这是一个与服务进程一起的专用进程。然后,sidecar 可以处理诸如重试之类的机制。
Sidecar 方法的优点是您不会将业务逻辑与弹性逻辑混为一谈。您可以在不涉及太多应用程序代码的情况下替换 sidecar 技术。此外,您可以轻松修改和调整 sidecar 配置,而无需重新部署服务。缺点在于无法使用特定模式,例如用于线程池隔离的隔板模式( bulkhead)。此外,后备值等模式在很大程度上取决于您的业务逻辑。扩展现有代码库也可能比添加新的基础架构组件更容易。
概括
在这篇文章中,我们看到了松散耦合、隔离、延迟控制和监督如何对系统弹性产生积极影响。重试模式可以处理可以通过多次尝试来纠正的通信错误。回退模式有助于在本地解决通信故障。超时模式提供了延迟的上限。断路器解决了在持续通信错误的情况下由于重试和快速回退而导致的意外拒绝服务攻击的问题。
像 Vert.x 这样的框架提供了一些开箱即用的弹性模式。还有可以与任何框架一起使用的专用弹性库。另一方面,服务网格作为在基础设施级别引入弹性模式的选项而存在。与往常一样,没有万能的解决方案,您的团队应该找出最适合他们的解决方案。
原文:https://blog.codecentric.de/en/2019/06/resilience-design-patterns-retry…
- 94 次浏览